Index Types
MongoDB provides a number of different index types. You can create indexes on any field or embedded field within a document or sub-document. You can create single field indexes or compound indexes. MongoDB also supports indexes of arrays, called multi-key indexes, as well as supports indexes on geospatial data. In general, you should create indexes that support your common and user-facing queries. Having these indexes will ensure that MongoDB scans the smallest possible number of documents. In the mongo shell, you can create an index by calling the ensureIndex() method.
Behavior of Indexes – All indexes in MongoDB are B-tree indexes, which can efficiently support equality matches and range queries. The index stores items internally in order sorted by the value of the index field. The ordering of index entries supports efficient range-based operations and allows MongoDB to return sorted results using the order of documents in the index.
Ordering of Indexes – MongoDB indexes may be ascending, (i.e. 1) or descending (i.e. -1) in their ordering. Nevertheless, MongoDB may also traverse the index in either directions. As a result, for single-field indexes, ascending and descending indexes are interchangeable. This is not the case for compound indexes: in compound indexes, the direction of the sort order can have a greater impact on the results.
Index Intersection – MongoDB can use the intersection of indexes to fulfill queries with compound conditions.
Limits – Certain restrictions apply to indexes, such as the length of the index keys or the number of indexes per collection.
Single Field Indexes
MongoDB provides complete support for indexes on any field in a collection of documents. By default, all collections have an index on the _id field, and applications and users may add additional indexes to support important queries and operations.
MongoDB supports indexes that contain either a single field or multiple fields depending on the operations that this index-type supports. This document describes indexes that contain a single field. Consider the following illustration of a single field index.
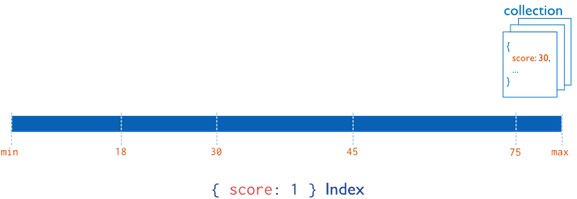
As an example, given the following document in the friends collection
{ “_id” : ObjectId(…),
“name” : “Alice”
“age” : 27
}
The following command creates an index on the name field
db.friends.ensureIndex( { “name” : 1 } )
_id Field Index – MongoDB creates the _id index, which is an ascending unique index on the _id field, for all collections when the collection is created. You cannot remove the index on the _id field. Think of the _id field as the primary key for a collection. Every document must have a unique _id field. You may store any unique value in the _id field. The default value of _id is an ObjectId which is generated when the client inserts the document. An ObjectId is a 12-byte unique identifier suitable for use as the value of an _id field.
In sharded clusters, if you do not use the _id field as the shard key, then your application must ensure the uniqueness of the values in the _id field to prevent errors. This is most-often done by using a standard auto-generated ObjectId.
Before version 2.2, capped collections did not have an _id field. In version 2.2 and newer, capped collections do have an _id field, except those in the local database.
Indexes on Embedded Fields – You can create indexes on fields embedded in sub-documents, just as you can index top-level fields in documents. Indexes on embedded fields differ from indexes on sub-documents, which include the full content up to the maximum index size of the sub-document in the index. Instead, indexes on embedded fields allow you to use a “dot notation,” to introspect into sub-documents. Consider a collection named people that holds documents that resemble the following example document
{“_id”: ObjectId(…)
“name”: “John Doe”
“address”: {
“street”: “Main”,
“zipcode”: “53511”,
“state”: “WI”
}
}
You can create an index on the address.zipcode field, using the following specification
db.people.ensureIndex( { “address.zipcode”: 1 } )
Indexes on Subdocuments – You can also create indexes on subdocuments. For example, the factories collection contains documents that contain a metro field, such as:
{ _id: ObjectId(…),
metro: {
city: “New York”,
state: “NY”
},
name: “Giant Factory”
}
The metro field is a subdocument, containing the embedded fields city and state. The following command creates an index on the metro field as a whole
db.factories.ensureIndex( { metro: 1 } )
The following query can use the index on the metro field
db.factories.find( { metro: { city: “New York”, state: “NY” } } )
This query returns the above document. When performing equality matches on subdocuments, field order matters and the subdocuments must match exactly. For example, the following query does not match the above document
db.factories.find( { metro: { state: “NY”, city: “New York” } } )
Compound Indexes
MongoDB supports compound indexes, where a single index structure holds references to multiple fields within a collection’s documents. The following diagram illustrates an example of a compound index on two fields
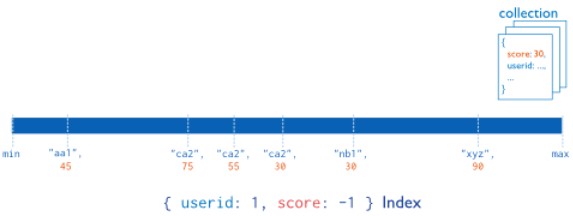
Diagram of a compound index on the userid field (ascending) and the score field (descending). The index sorts first by the userid field and then by the score field. MongoDB imposes a limit of 31 fields for any compound index. Compound indexes can support queries that match on multiple fields. Consider a collection named products that holds documents that resemble the following document.
{ “_id”: ObjectId(…),
“item”: “Banana”,
“category”: [“food”, “produce”, “grocery”],
“location”: “4th Street Store”,
“stock”: 4,
“type”: “cases”,
“arrival”: Date(…) }
If applications query on the item field as well as query on both the item field and the stock field, you can specify a single compound index to support both of these queries
db.products.ensureIndex( { “item”: 1, “stock”: 1 } )
You may not create compound indexes that have hashed index fields. You will receive an error if you attempt to create a compound index that includes a hashed index. The order of the fields in a compound index is very important. In the previous example, the index will contain references to documents sorted first by the values of the item field and, within each value of the item field, sorted by values of the stock field.
In addition to supporting queries that match on all the index fields, compound indexes can support queries that match on the prefix of the index fields.
Sort Order – Indexes store references to fields in either ascending (1) or descending (-1) sort order. For single-field indexes, the sort order of keys doesn’t matter because MongoDB can traverse the index in either direction. However, for compound indexes, sort order can matter in determining whether the index can support a sort operation. Consider a collection events that contains documents with the field username and date. Applications can issue queries that return results sorted first by ascending username values and then by descending (i.e. more recent to last) date values, such as
db.events.find().sort( { username: 1, date: -1 } )
or queries that return results sorted first by descending username values and then by ascending date values, such as
db.events.find().sort( { username: -1, date: 1 } )
The following index can support both these sort operations
db.events.ensureIndex( { “username” : 1, “date” : -1 } )
However, the above index cannot support sorting by ascending username values and then by ascending date values, such as the following
db.events.find().sort( { username: 1, date: 1 } )
Prefixes – Compound indexes support queries on any prefix of the index fields. Index prefixes are the beginning subset of indexed fields. For example, given the index { a: 1, b: 1, c: 1 }, both { a: 1 } and { a: 1, b: 1 } are prefixes of the index. If you have a collection that has a compound index on { a: 1, b: 1 }, as well as an index that consists of the prefix of that index, i.e. { a: 1 }, assuming none of the index has a sparse or unique constraints, then you can drop the { a: 1 } index. MongoDB will be able to use the compound index in all of situations that it would have used the { a: 1 } index. For example, given the following index
{ “item”: 1, “location”: 1, “stock”: 1 }
MongoDB can use this index to support queries that include
- the item field,
- the item field and the location field,
- the item field and the location field and the stock field, or
- only the item and stock fields; however, this index would be less efficient than an index on only item and stock.
MongoDB cannot use this index to support queries that include:
- only the location field,
- only the stock field, or
- only the location and stock fields.
Index Intersection – Starting in version 2.6, MongoDB can use index intersection to fulfill queries. The choice between creating compound indexes that support your queries or relying on index intersection depends on the specifics of your system.
Multikey Indexes
To index a field that holds an array value, MongoDB adds index items for each item in the array. These multikey indexes allow MongoDB to return documents from queries using the value of an array. MongoDB automatically determines whether to create a multikey index if the indexed field contains an array value; you do not need to explicitly specify the multikey type.
Consider the following illustration of a multikey index
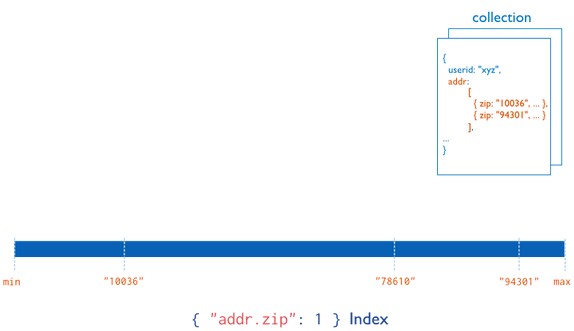
Diagram of a multikey index on the addr.zip field. The addr field contains an array of address documents. The address documents contain the zip field.
Multikey indexes support all operations supported by other MongoDB indexes; however, applications may use multikey indexes to select documents based on ranges of values for the value of an array. Multikey indexes support arrays that hold both values (e.g. strings, numbers) and nested documents.
Limitations
Interactions between Compound and Multikey Indexes – While you can create multikey compound indexes, at most one field in a compound index may hold an array. For example, given an index on { a: 1, b: 1 }, the following documents are permissible:
{a: [1, 2], b: 1}
{a: 1, b: [1, 2]}
However, the following document is impermissible, and MongoDB cannot insert such a document into a collection with the {a: 1, b: 1 } index:
{a: [1, 2], b: [1, 2]}
If you attempt to insert a such a document, MongoDB will reject the insertion, and produce an error that says cannot index parallel arrays. MongoDB does not index parallel arrays because they require the index to include each value in the Cartesian product of the compound keys, which could quickly result in incredibly large and difficult to maintain indexes.
Shard Keys – The index of a shard key cannot be a multi-key index.
Hashed Indexes – Hashed indexes are not compatible with multi-key indexes. To compute the hash for a hashed index, MongoDB collapses sub-documents and computes the hash for the entire value. For fields that hold arrays or sub-documents, you cannot use the index to support queries that introspect the sub-document.
Examples
Index Basic Arrays – Given the following document:
{
“_id” : ObjectId(“…”),
“name” : “Warm Weather”,
“author” : “Steve”,
“tags” : [ “weather”, “hot”, “record”, “april” ]
}
Then an index on the tags field, { tags: 1 }, would be a multikey index and would include these four separate entries for that document:
“weather”,
“hot”,
“record”, and
“april”.
Queries could use the multikey index to return queries for any of the above values.
Index Arrays with Embedded Documents – You can create multikey indexes on fields in objects embedded in arrays, as in the following example:
Consider a feedback collection with documents in the following form:
{
“_id”: ObjectId(…),
“title”: “Grocery Quality”,
“comments”: [
{ author_id: ObjectId(…),
date: Date(…),
text: “Please expand the cheddar selection.” },
{ author_id: ObjectId(…),
date: Date(…),
text: “Please expand the mustard selection.” },
{ author_id: ObjectId(…),
date: Date(…),
text: “Please expand the olive selection.” }
]
}
An index on the comments.text field would be a multikey index and would add items to the index for all embedded documents in the array.
With the index { “comments.text”: 1 } on the feedback collection, consider the following query:
db.feedback.find( { “comments.text”: “Please expand the olive selection.” } )
The query would select the documents in the collection that contain the following embedded document in the comments array:
{ author_id: ObjectId(…),
date: Date(…),
text: “Please expand the olive selection.” }
Geospatial Indexes and Queries
MongoDB offers a number of indexes and query mechanisms to handle geospatial information. This section introduces MongoDB’s geospatial features.
Surfaces – Before storing your location data and writing queries, you must decide the type of surface to use to perform calculations. The type you choose affects how you store data, what type of index to build, and the syntax of your queries. MongoDB offers two surface types:
Spherical – To calculate geometry over an Earth-like sphere, store your location data on a spherical surface and use 2dsphere index. Store your location data as GeoJSON objects with this coordinate-axis order: longitude, latitude. The coordinate reference system for GeoJSON uses the WGS84 datum.
Flat – To calculate distances on a Euclidean plane, store your location data as legacy coordinate pairs and use a 2d index.
Location Data – If you choose spherical surface calculations, you store location data as either:
GeoJSON Objects – Queries on GeoJSON objects always calculate on a sphere. The default coordinate reference system for GeoJSON uses the WGS84 datum. New in version 2.4: Support for GeoJSON storage and queries is new in version 2.4. Prior to version 2.4, all geospatial data used coordinate pairs.
MongoDB supports the following GeoJSON objects
- Point
- LineString
- Polygon
Legacy Coordinate Pairs – MongoDB supports spherical surface calculations on legacy coordinate pairs using a 2dsphere index by converting the data to the GeoJSON Point type.
If you choose flat surface calculations, and use a 2d index you can store data only as legacy coordinate pairs.
Query Operations – MongoDB’s geospatial query operators let you query for
Inclusion – MongoDB can query for locations contained entirely within a specified polygon. Inclusion queries use the $geoWithin operator. Both 2d and 2dsphere indexes can support inclusion queries. MongoDB does not require an index for inclusion queries after 2.2.3; however, these indexes will improve query performance.
Intersection – MongoDB can query for locations that intersect with a specified geometry. These queries apply only to data on a spherical surface. These queries use the $geoIntersects operator. Only 2dsphere indexes support intersection.
Proximity – MongoDB can query for the points nearest to another point. Proximity queries use the $near operator. The $near operator requires a 2d or 2dsphere index.
Geospatial Indexes – MongoDB provides the following geospatial index types to support the geospatial queries.
2dsphere – 2dsphere indexes support:
- Calculations on a sphere
- GeoJSON objects and include backwards compatibility for legacy coordinate pairs.
- A compound index with scalar index fields (i.e. ascending or descending) as a prefix or suffix of the 2dsphere index field
New in version 2.4: 2dsphere indexes are not available before version 2.4.
2d – 2d indexes support:
- Calculations using flat geometry
- Legacy coordinate pairs (i.e., geospatial points on a flat coordinate system)
- A compound index with only one additional field, as a suffix of the 2d index field
Geospatial Indexes and Sharding – You cannot use a geospatial index as the shard key index. You can create and maintain a geospatial index on a sharded collection if using fields other than shard key. Queries using $near are not supported for sharded collections. Use geoNear instead. You also can query for geospatial data using $geoWithin.
Text Indexes
They are new in version 2.4. MongoDB provides text indexes to support text search of string content in documents of a collection. text indexes can include any field whose value is a string or an array of string elements. To perform queries that access the text index, use the $text query operator. Changed in version 2.6: MongoDB enables the text search feature by default. In MongoDB 2.4, you need to enable the text search feature manually to create text indexes and perform text search.
Create Text Index – To create a text index, use the db.collection.ensureIndex() method. To index a field that contains a string or an array of string elements, include the field and specify the string literal “text” in the index document, as in the following example:
db.reviews.ensureIndex( { comments: “text” } )
A collection can have at most one text index.
Supported Languages and Stop Words – MongoDB supports text search for various languages. text indexes drop language-specific stop words (e.g. in English, “the,” “an,” “a,” “and,” etc.) and uses simple language-specific suffix stemming. If the index language is English, text indexes are case-insensitive for non-diacritics; i.e. case insensitive for [A-z].
Restrictions
Text Search and Hints – You cannot use hint() if the query includes a $text query expression.
Compound Index – A compound index can include a text index key in combination with ascending/descending index keys. However, these compound indexes have the following restrictions
- A compound text index cannot include any other special index types, such as multi-key or geospatial index fields.
- If the compound text index includes keys preceding the text index key, to perform a $text search, the query predicate must include equality match conditions on the preceding keys.
Storage Requirements and Performance Costs – text indexes have the following storage requirements and performance costs:
- text indexes change the space allocation method for all future record allocations in a collection to usePowerOf2Sizes.
- text indexes can be large. They contain one index entry for each unique post-stemmed word in each indexed field for each document inserted.
- Building a text index is very similar to building a large multi-key index and will take longer than building a simple ordered (scalar) index on the same data.
- When building a large text index on an existing collection, ensure that you have a sufficiently high limit on open file descriptors.
- text indexes will impact insertion throughput because MongoDB must add an index entry for each unique post-stemmed word in each indexed field of each new source document.
- Additionally, text indexes do not store phrases or information about the proximity of words in the documents. As a result, phrase queries will run much more effectively when the entire collection fits in RAM.
Text Search – Text search supports the search of string content in documents of a collection. MongoDB provides the $text operator to perform text search in queries and in aggregation pipelines. The text search process is as
- tokenizes and stems the search term(s) during both the index creation and the text command execution.
- assigns a score to each document that contains the search term in the indexed fields. The score determines the relevance of a document to a given search query.
The $text operator can search for words and phrases. The query matches on the complete stemmed words. For example, if a document field contains the word blueberry, a search on the term blue will not match the document. However, a search on either blueberry or blueberries will match.
Hashed Index
It is new in version 2.4. Hashed indexes maintain entries with hashes of the values of the indexed field. The hashing function collapses sub-documents and computes the hash for the entire value but does not support multi-key (i.e. arrays) indexes. Hashed indexes support sharding a collection using a hashed shard key. Using a hashed shard key to shard a collection ensures a more even distribution of data.
MongoDB can use the hashed index to support equality queries, but hashed indexes do not support range queries. You may not create compound indexes that have hashed index fields or specify a unique constraint on a hashed index; however, you can create both a hashed index and an ascending/descending (i.e. non-hashed) index on the same field: MongoDB will use the scalar index for range queries.
MongoDB hashed indexes truncate floating point numbers to 64-bit integers before hashing. For example, a hashed index would store the same value for a field that held a value of 2.3, 2.2, and 2.9. To prevent collisions, do not use a hashed index for floating point numbers that cannot be reliably converted to 64-bit integers (and then back to floating point). MongoDB hashed indexes do not support floating point values larger than 253.
Create a hashed index using an operation that resembles the following
db.active.ensureIndex( { a: “hashed” } )
This operation creates a hashed index for the active collection on the field.
Apply for MongoDB Certification Now!!
https://www.vskills.in/certification/databases/mongodb-server-administrator
