Document Structure
Data in MongoDB has a flexible schema. Unlike SQL databases, where user must determine and declare a table’s schema before inserting data, MongoDB’s collections do not enforce document structure. This flexibility facilitates the mapping of documents to an entity or an object. Each document can match the data fields of the represented entity, even if the data has substantial variation. In practice, however, the documents in a collection share a similar structure.
The key challenge in data modeling is balancing the needs of the application, the performance characteristics of the database engine, and the data retrieval patterns. When designing data models, always consider the application usage of the data (i.e. queries, updates, and processing of the data) as well as the inherent structure of the data itself.
The key decision in designing data models for MongoDB applications revolves around the structure of documents and how the application represents relationships between data. There are two tools that allow applications to represent these relationships references and embedded documents.
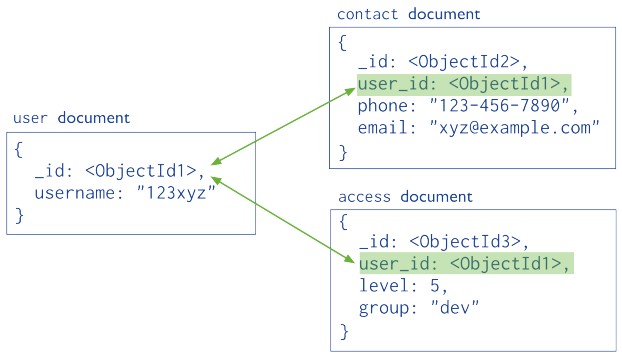
References – References store the relationships between data by including links or references from one document to another. Applications can resolve these references) to access the related data. Broadly, these are normalized data models.
Data model using references to link documents. Both the contact document and the access document contain a reference to the user document.
Embedded Data – Embedded documents capture relationships between data by storing related data in a single document structure. MongoDB documents make it possible to embed document structures as sub-documents in a field or array within a document. These de-normalized data models allow applications to retrieve and manipulate related data in a single database operation.
Issues in Data Modeling – Issues with data modeling in MongoDB are
- Atomicity of Write Operations – In MongoDB, write operations are atomic at the document level, and no single write operation can atomically affect more than one document or more than one collection. A de-normalized data model with embedded data combines all related data for a represented entity in a single document. This facilitates atomic write operations since a single write operation can insert or update the data for an entity. Normalizing the data would split the data across multiple collections and would require multiple write operations that are not atomic collectively.
- Document Growth – Some updates, such as pushing elements to an array or adding new fields, increase a document’s size. If the document size exceeds the allocated space for that document, MongoDB relocates the document on disk. The growth consideration can affect the decision to normalize or de-normalize data.
- Data Use and Performance – When designing a data model, consider how applications will use database. If application needs are mainly read operations to a collection, adding indexes to support common queries can improve performance.
Apply for MongoDB Certification Now!!
https://www.vskills.in/certification/databases/mongodb-server-administrator
