It is the master that arbitrates all the available cluster resources, thereby helping manage the distributed applications running on the YARN system. It works together with the per-node NodeManagers and the per-application ApplicationMasters.
In YARN, the ResourceManager is primarily limited to scheduling—that is, it allocates available resources in the system among the competing applications but does not concern itself with per-application state management. The scheduler handles only an overall resource profile for each application, ignoring local optimizations and internal application f low. In fact, YARN completely departs from the static assignment of map and reduce slots because it treats the cluster as a resource pool. Because of this clear separation of responsibilities coupled with the modularity described previously, the ResourceManager is able to address the important design requirements of scalability and support for alternative programming paradigms.
In contrast to many other workflow schedulers, the ResourceManager also has the ability to symmetrically request back resources from a running application. This situation typically happens when cluster resources become scarce and the scheduler decides to reclaim some (but not all) of the resources that were given to an application.
In YARN, ResourceRequests can be strict or negotiable. This feature provides ApplicationMasters with a great deal of f lexibility on how to fulfill the reclamation requests—for example, by picking containers to reclaim that are less crucial for the computation, by checkpointing the state of a task, or by migrating the computation to other running containers. Overall, this scheme allows applications to preserve work, in contrast to platforms that kill containers to satisfy resource constraints. If the application is noncollaborative, the ResourceManager can, after waiting a certain amount of time, obtain the needed resources by instructing the NodeManagers to forcibly terminate containers.
ResourceManager failures remain significant events affecting cluster availability. As of this writing, the ResourceManager will restart running ApplicationMasters as it recovers its state. If the framework supports restart capabilities—and most will for routine fault tolerance—the platform will automatically restore users’ pipelines.
In contrast to the Hadoop 1.0 JobTracker, it is important to mention the tasks for which the ResourceManager is not responsible. Other than tracking application execution f low and task fault tolerance, the ResourceManager will not provide access to the application status (servlet; now part of the ApplicationMaster) or track previously executed jobs, a responsibility that is now delegated to the JobHistoryService (a daemon running on a separated node). This is consistent with the view that the ResourceManager should handle only live resource scheduling, and helps YARN central components scale better than Hadoop 1.0 JobTracker.
It works together with the following components
- The per-node NodeManagers, which take instructions from the Resource-Manager, manage resources available on a single node, and accept container requests from ApplicationMasters
- The per-application ApplicationMasters, which are responsible for negotiating resources with the ResourceManager and for working with the NodeManagers to start, monitor, and stop the containers
The ResourceManager components are
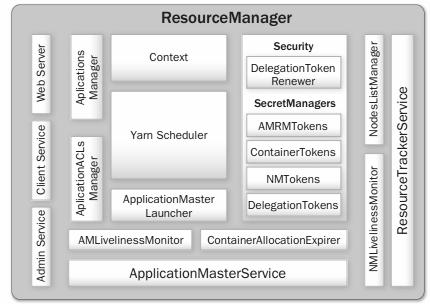
Client Service – This service implements ApplicationClientProtocol, the basic client interface to the ResourceManager. This component handles all the remote procedure call (RPC) communications to the ResourceManager from the clients, including operations such as
- Application submission
- Application termination
- Exposing information about applications, queues, cluster statistics, user ACLs, and more
Client Service provides additional protection to the ResourceManager depending on whether the administrator configured YARN to run in secure or nonsecure mode. In secure mode, the Client Service makes sure that all incoming requests from users are authenticated (for example, by Kerberos) and then authorizes each user by looking up application-level Access Control Lists (ACLs) and subsequently queue-level ALCs. For all clients that cannot be authenticated with Kerberos directly, this service also exposes APIs to obtain what are known as the ResourceManager delegation tokens. Delegation tokens are special objects that a Kerberos-authenticated client can first obtain by securely communicating with the ResourceManager and then pass along to its nonauthenticated processes. Any client process that has a handle to these delegation tokens can communicate with ResourceManager securely without separately authenticating with Kerberos first.
Administration Service – While Client Service is responsible for typical user invocations like application submission and termination, there is a list of activities that administrators of a YARN cluster have to perform from time to time. To make sure that administration requests don’t get starved by the regular users’ requests and to give the operators’ commands a higher priority, all of the administrative operations are served via a separate interface called Administration Service. ResourceManagerAdministrationProtocol is the communication protocol that is implemented by this component. Some of the important administrative operations are
- Refreshing queues: for example, adding new queues, stopping existing queues, and reconfiguring queues to change some of their properties like capacities, limits, and more
- Refreshing the list of nodes handled by the ResourceManager: for example, adding newly installed nodes or decommissioning existing nodes for various reasons
- Adding new user-to-group mappings, adding/updating administrator ACLs, modifying the list of superusers, and so on
Both Client Service and Administration Service work closely with Application-Manager for ACL enforcement.
Application ACLs Manager – The ResourceManager needs to gate the user-facing APIs like the client and administrative requests so that they are accessible only to authorized users. This component maintains the ACLs per application and enforces them. Application ACLs are enabled on the ResourceManager by setting to true the configuration property yarn.acl.enable. There are two types of application accesses: (1) viewing and (2) modifying an application. ACLs against the view access determine who can “view” some or all of the application-related details on the RPC interfaces, web UI, and web services. The modify-application ACLs determine who can “modify” the application (e.g., kill the application).
ResourceManager Web Application and Web Services – The ResourceManager has a web application that exposes information about the state of the cluster; metrics; lists of active, healthy, and unhealthy nodes; lists of applications, their state and status; hyper-references to the ApplicationMaster web interfaces; and a scheduler-specific interface.
ApplicationMasters Service – This component responds to requests from all the ApplicationMasters. It implements ApplicationMasterProtocol, which is the one and only protocol that ApplicationMasters use to communicate with the ResourceManager. It is responsible for
- Registration of new ApplicationMasters
- Termination/unregistering of requests from any finishing ApplicationMasters
- Authorizing all requests from various ApplicationMasters to make sure that only valid ApplicationMasters are sending requests to the corresponding Application entity residing in the ResourceManager
- Obtaining container allocation and deallocation requests from all running ApplicationMasters and forwarding them asynchronously to the YarnScheduler
The ApplicationMasterService has additional logic to make sure that—at any point in time—only one thread in any ApplicationMaster can send requests to the ResourceManager. All the RPCs from ApplicationMasters are serialized on the ResourceManager, so it is expected that only one thread in the ApplicationMaster will make these requests.
ApplicationMaster Liveliness Monitor – To help manage the list of live ApplicationMasters and dead/non-responding ApplicationMasters, this monitor keeps track of each ApplicationMaster and its last heartbeat time. Any ApplicationMaster that does not produce a heartbeat within a configured interval of time—by default, 10 minutes—is deemed dead and is expired by the ResourceManager. All containers currently running/allocated to an expired ApplicationMaster are marked as dead. The ResourceManager reschedules the same application to run a new Application Attempt on a new container, allowing up to a maximum of two such attempts by default.
Resource Tracker Service – NodeManagers periodically send heartbeats to the ResourceManager, and this component of the ResourceManager is responsible for responding to such RPCs from all the nodes. It implements the ResourceTracker interface to which all NodeManagers communicate. Specifically, it is responsible for
- Registering new nodes
- Accepting node heartbeats from previously registered nodes
- Ensuring that only “valid” nodes can interact with the ResourceManager and rejecting any other nodes
Before and during the registration of a new node to the system, lots of things happen. The administrators are supposed to install YARN on the node along with any other dependencies, and configure the node to communicate to its ResourceManager by setting up configuration similar to other existing nodes. If needed, this node should be removed from the excluded nodes list of the ResourceManager. The ResourceManager will reject requests from any invalid or decommissioned nodes. Nodes that don’t respect the ResourceManager’s configuration for minimum resource requirements will also be rejected.
NodeManagers Liveliness Monitor – To keep track of live nodes and specifically identify any dead nodes, this component keeps track of each node’s identifier (ID) and its last heartbeat time. Any node that doesn’t send a heartbeat within a configured interval of time—by default, 10 minutes—is deemed dead and is expired by the ResourceManager. All the containers currently running on an expired node are marked as dead, and no new containers are scheduled on such node. Once such a node restarts (either automatically or by administrators’ intervention) and reregisters, it will again be considered for scheduling.
Nodes-List Manager – The nodes-list manager is a collection in the ResourceManager’s memory of both valid and excluded nodes. It is responsible for reading the host configuration files specified via the yarn.resourcemanager.nodes.include-path and yarn.resourcemanager.nodes.exclude-path configuration properties and seeding the initial list of nodes based on those files. It also keeps track of nodes that are explicitly decommissioned by administrators as time progresses.
ApplicationsManager – The ApplicationsManager is responsible for maintaining a collection of submitted applications. After application submission, it first validates the application’s specifications and rejects any application that requests unsatisfiable resources for its ApplicationMaster (i.e., there is no node in the cluster that has enough resources to run the ApplicationMaster itself ). It then ensures that no other application was already submitted with the same application ID—a scenario that can be caused by an erroneous or a malicious client. Finally, it forwards the admitted application to the scheduler.
This component is also responsible for recording and managing finished applications for a while before they are completely evacuated from the ResourceManager’s memory. When an application finishes, it places an ApplicationSummary in the daemon’s log file. The ApplicationSummary is a compact representation of application information at the time of completion.
ApplicationMaster Launcher – In YARN, while every other container’s launch is initiated by an ApplicationMaster, the ApplicationMaster itself is allocated and prepared for launch on a NodeManager by the ResourceManager itself. The ApplicationMaster Launcher is responsible for this job. This component maintains a thread pool to set up the environment and to communicate with NodeManagers so as to launch ApplicationMasters of newly submitted applications as well as applications for which previous ApplicationMaster attempts failed for some reason. It is also responsible for talking to NodeManagers about cleaning up the ApplicationMaster—mainly killing the process by signaling the corresponding NodeManager when an application finishes normally or is forcefully terminated.
YarnScheduler – The YarnScheduler is responsible for allocating resources to the various running applications subject to constraints of capacities, queues, and so on. It performs its scheduling function based on the resource requirements of the applications, such as memory, CPU, disk, and network needs. Currently, memory and CPU cores are supported resources.
ContainerAllocationExpirer – This component is in charge of ensuring that all allocated containers are eventually used by ApplicationMasters and subsequently launched on the corresponding NodeManagers. ApplicationMasters run as untrusted user code and may potentially hold on to allocations without using them; as such, they can lead to under-utilization and abuse of a cluster’s resources. To address this, the ContainerAllocationExpirer maintains a list of containers that are allocated but still not used on the corresponding NodeManagers. For any container, if the corresponding NodeManager doesn’t report to the ResourceManager that the container has started running within a configured interval of time (by default, 10 minutes), the container is deemed dead and is expired by the ResourceManager.
