Hadoop can perform only batch processing, and data will be accessed only in a sequential manner. That means one has to search the entire dataset even for the simplest of jobs. A huge dataset when processed results in another huge data set, which should also be processed sequentially. At this point, a new solution is needed to access any point of data in a single unit of time (random access).
Applications such as HBase, Cassandra, couchDB, Dynamo, and MongoDB are some of the databases that store huge amounts of data and access the data in a random manner.
HBase is a column-oriented database management system that runs on top of HDFS. It is well suited for sparse data sets, which are common in many big data use cases. Unlike relational database systems, HBase does not support a structured query language like SQL; in fact, HBase isn’t a relational data store at all. HBase applications are written in Java much like a typical MapReduce application. HBase does support writing applications in Avro, REST, and Thrift.
Features
- Linear and modular scalability.
- Strictly consistent reads and writes.
- Automatic and configurable sharding of tables
- Automatic failover support between RegionServers.
- Convenient base classes for backing Hadoop MapReduce jobs with Apache HBase tables.
- Easy to use Java API for client access.
- Block cache and Bloom Filters for real-time queries.
- Query predicate push down via server side Filters
- Thrift gateway and a REST-ful Web service that supports XML, Protobuf, and binary data encoding options
- Extensible jruby-based (JIRB) shell
- Support for exporting metrics via the Hadoop metrics subsystem to files or Ganglia; or via JMX
- Strongly consistent reads/writes: HBase is not an “eventually consistent” DataStore. This makes it very suitable for tasks such as high-speed counter aggregation.
- Automatic sharding: HBase tables are distributed on the cluster via regions, and regions are automatically split and re-distributed as your data grows.
- Automatic RegionServer failover
- Hadoop/HDFS Integration: HBase supports HDFS out of the box as its distributed file system.
- MapReduce: HBase supports massively parallelized processing via MapReduce for using HBase as both source and sink.
- Java Client API: HBase supports an easy to use Java API for programmatic access.
- Thrift/REST API: HBase also supports Thrift and REST for non-Java front-ends.
- Block Cache and Bloom Filters: HBase supports a Block Cache and Bloom Filters for high volume query optimization.
- Operational Management: HBase provides build-in web-pages for operational insight as well as JMX metrics.
An HBase system comprises a set of tables. Each table contains rows and columns, much like a traditional database. Table is a collection of rows. Each table must have an element defined as a Primary Key, and all access attempts to HBase tables must use this Primary Key. An HBase column represents an attribute of an object; for example, if the table is storing diagnostic logs from servers in your environment, where each row might be a log record, a typical column in such a table would be the timestamp of when the log record was written, or perhaps the server name where the record originated. In fact, HBase allows for many attributes to be grouped together into what are known as column families, such that the elements of a column family are all stored together. This is different from a row-oriented relational database, where all the columns of a given row are stored together. With HBase you must predefine the table schema and specify the column families. Row is a collection of column families. However, it’s very flexible in that new columns can be added to families at any time, making the schema flexible and therefore able to adapt to changing application requirements.
HBase is an open source, non-relational, distributed database modeled after Google’s BigTable and written in Java. It is developed as part of Apache Software Foundation’s Apache Hadoop project and runs on top of HDFS (Hadoop Distributed Filesystem), providing BigTable-like capabilities for Hadoop. That is, it provides a fault-tolerant way of storing large quantities of sparse data (small amounts of information caught within a large collection of empty or unimportant data, such as finding the 50 largest items in a group of 2 billion records, or finding the non-zero items representing less than 0.1% of a huge collection).
HBase features compression, in-memory operation, and Bloom filters on a per-column basis as outlined in the original BigTable paper. Tables in HBase can serve as the input and output for MapReduce jobs run in Hadoop, and may be accessed through the Java API but also through REST, Avro or Thrift gateway APIs.
HBase is a type of “NoSQL” database. “NoSQL” is a general term meaning that the database isn’t an RDBMS which supports SQL as its primary access language, but there are many types of NoSQL databases: BerkeleyDB is an example of a local NoSQL database, whereas HBase is very much a distributed database. Technically speaking, HBase is really more a “Data Store” than “Data Base” because it lacks many of the features you find in an RDBMS, such as typed columns, secondary indexes, triggers, and advanced query languages, etc.
However, HBase has many features which supports both linear and modular scaling. HBase clusters expand by adding RegionServers that are hosted on commodity class servers. If a cluster expands from 10 to 20 RegionServers, for example, it doubles both in terms of storage and as well as processing capacity. An RDBMS can scale well, but only up to a point – specifically, the size of a single database server – and for the best performance requires specialized hardware and storage devices.
HBase is a column-oriented data store, meaning it stores data by columns rather than by rows. This makes certain data access patterns much less expensive than with traditional row-oriented relational database systems. For example, in HBase if there is no data for a given column family, it simply does not store anything at all; contrast this with a relational database which must store null values explicitly. In addition, when retrieving data in HBase, you should only ask for the specific column families you need; because there can literally be millions of columns in a given row, you need to make sure you ask only for the data you actually need.
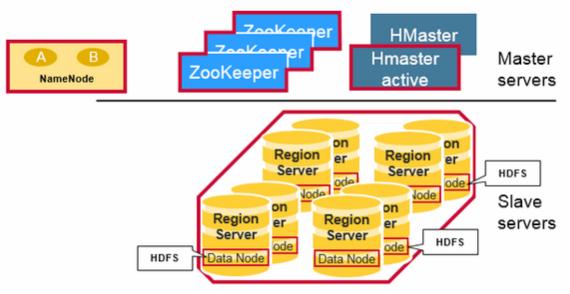
Physically, HBase is composed of three types of servers in a master slave type of architecture. Region servers serve data for reads and writes. When accessing data, clients communicate with HBase RegionServers directly. Region assignment, DDL (create, delete tables) operations are handled by the HBase Master process. Zookeeper, which is part of HDFS, maintains a live cluster state.
Architectural Components and Working
The Hadoop DataNode stores the data that the Region Server is managing. All HBase data is stored in HDFS files. Region Servers are collocated with the HDFS DataNodes, which enable data locality (putting the data close to where it is needed) for the data served by the RegionServers. HBase data is local when it is written, but when a region is moved, it is not local until compaction. The NameNode maintains metadata information for all the physical data blocks that comprise the files.
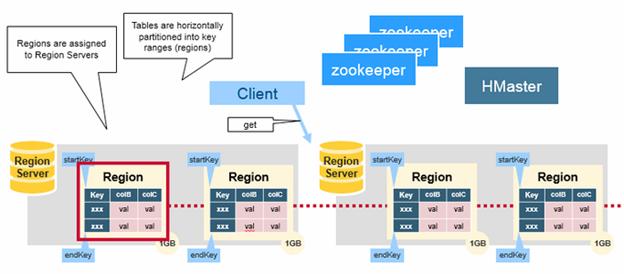
Regions – HBase Tables are divided horizontally by row key range into “Regions.” A region contains all rows in the table between the region’s start key and end key. Regions are assigned to the nodes in the cluster, called “Region Servers,” and these serve data for reads and writes. A region server can serve about 1,000 regions.
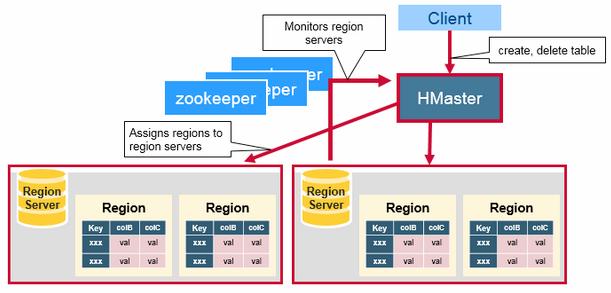
HBase HMaster – Region assignment, DDL (create, delete tables) operations are handled by the HBase Master. A master is responsible for:
- Coordinating the region servers
- Assigning regions on startup , re-assigning regions for recovery or load balancing
- Monitoring all RegionServer instances in the cluster (listens for notifications from zookeeper)
- Admin functions like interface for creating, deleting, updating tables
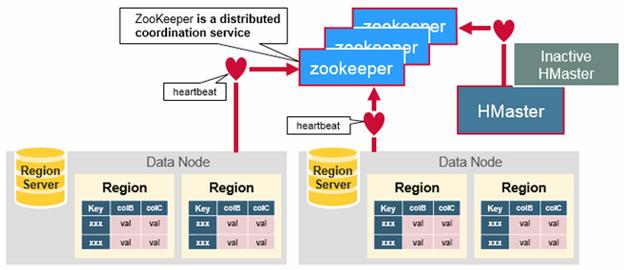
ZooKeeper – HBase uses ZooKeeper as a distributed coordination service to maintain server state in the cluster. Zookeeper maintains which servers are alive and available, and provides server failure notification. Zookeeper uses consensus to guarantee common shared state. Note that there should be three or five machines for consensus.
HFile – Data is stored in an HFile which contains sorted key/values. When the MemStore accumulates enough data, the entire sorted KeyValue set is written to a new HFile in HDFS. This is a sequential write. It is very fast, as it avoids moving the disk drive head. An HFile contains a multi-layered index which allows HBase to seek to the data without having to read the whole file. The multi-level index is like a b+tree:
- Key value pairs are stored in increasing order
- Indexes point by row key to the key value data in 64KB “blocks”
- Each block has its own leaf-index
- The last key of each block is put in the intermediate index
- The root index points to the intermediate index
The trailer points to the meta blocks, and is written at the end of persisting the data to the file. The trailer also has information like bloom filters and time range info. Bloom filters help to skip files that do not contain a certain row key. The time range info is useful for skipping the file if it is not in the time range the read is looking for.
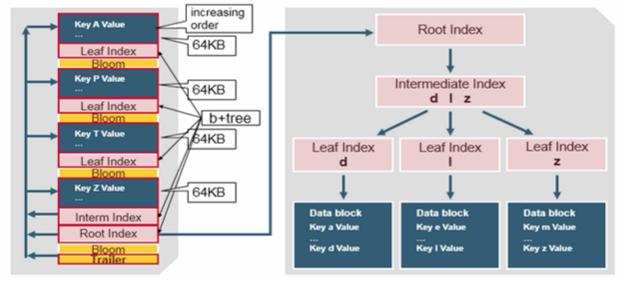
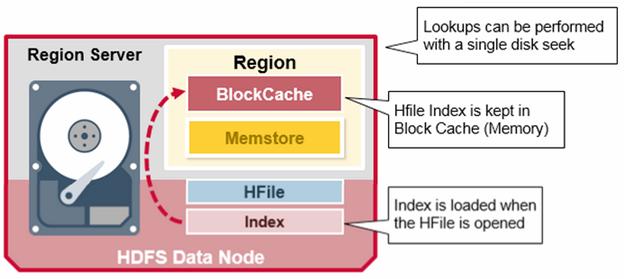
The index, is loaded when the HFile is opened and kept in memory. This allows lookups to be performed with a single disk seek.
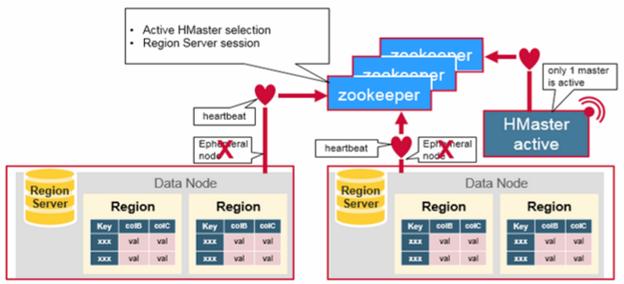
Components Working – Zookeeper is used to coordinate shared state information for members of distributed systems. Region servers and the active HMaster connect with a session to ZooKeeper. The ZooKeeper maintains ephemeral nodes for active sessions via heartbeats. Each Region Server creates an ephemeral node. The HMaster monitors these nodes to discover available region servers, and it also monitors these nodes for server failures. HMasters vie to create an ephemeral node. Zookeeper determines the first one and uses it to make sure that only one master is active. The active HMaster sends heartbeats to Zookeeper, and the inactive HMaster listens for notifications of the active HMaster failure.
If a region server or the active HMaster fails to send a heartbeat, the session is expired and the corresponding ephemeral node is deleted. Listeners for updates will be notified of the deleted nodes. The active HMaster listens for region servers, and will recover region servers on failure. The Inactive HMaster listens for active HMaster failure, and if an active HMaster fails, the inactive HMaster becomes active.
Regions contain an in-memory data store (MemStore) and a persistent data store (HFile), and all regions on a region server share a reference to the write-ahead log (WAL) which is used to store new data that hasn’t yet been persisted to permanent storage and to recover from region server crashes. Each region holds a specific range of row keys, and when a region exceeds a configurable size, HBase automatically splits the region into two child regions, which is the key to scaling HBase.
As a table grows, more and more regions are created and spread across the entire cluster. When clients request a specific row key or scan a range of row keys, HBase tells them the regions on which those keys exist, and the clients then communicate directly with the region servers where those regions exist. This design minimizes the number of disk seeks required to find any given row, and optimizes HBase toward disk transfer when returning data. This is in contrast to relational databases, which might need to do a large number of disk seeks before transferring data from disk, even with indexes.
The HDFS component is the Hadoop Distributed Filesystem, a distributed, fault-tolerant and scalable filesystem which guards against data loss by dividing files into blocks and spreading them across the cluster; it is where HBase actually stores data. Strictly speaking the persistent storage can be anything that implements the Hadoop FileSystem API, but usually HBase is deployed onto Hadoop clusters running HDFS. In fact, when you first download and install HBase on a single machine, it uses the local filesystem until you change the configuration!
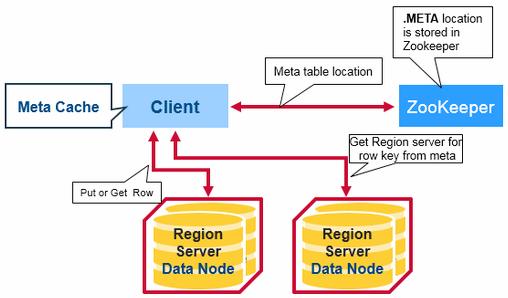
HBase First Data Access – There is a special HBase Catalog table called the META table, which holds the location of the regions in the cluster. ZooKeeper stores the location of the META table.
This is what happens the first time a client reads or writes to HBase:
The client gets the Region server that hosts the META table from ZooKeeper.
The client will query the .META. server to get the region server corresponding to the row key it wants to access. The client caches this information along with the META table location.
It will get the Row from the corresponding Region Server.
For future reads, the client uses the cache to retrieve the META location and previously read row keys. Over time, it does not need to query the META table, unless there is a miss because a region has moved; then it will re-query and update the cache.
HBase Write Steps – When the client issues a Put request, the first step is to write the data to the write-ahead log, the WAL
- Edits are appended to the end of the WAL file that is stored on disk.
- The WAL is used to recover not-yet-persisted data in case a server crashes.
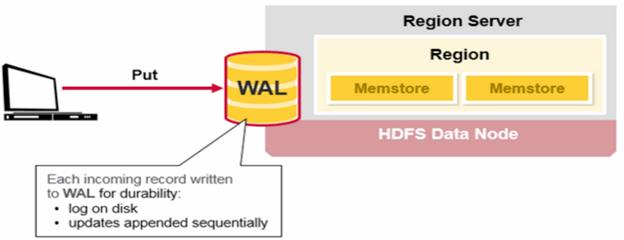
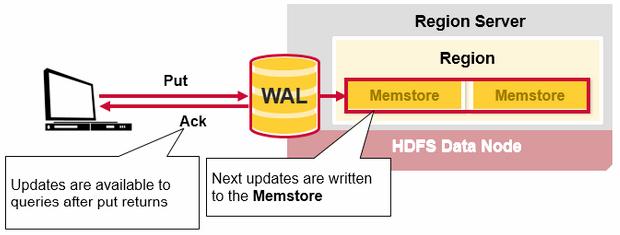
Once the data is written to the WAL, it is placed in the MemStore. Then, the put request acknowledgement returns to the client.
Data Model
In HBase, data is stored in tables, which have rows and columns. This is a terminology overlap with relational databases (RDBMSs), but this is not a helpful analogy. Instead, it can be helpful to think of an HBase table as a multi-dimensional map.
- Table – An HBase table consists of multiple rows. HBase organizes data into tables. Table names are Strings and composed of characters that are safe for use in a file system path.
- Row – A row in HBase consists of a row key and one or more columns with values associated with them. Rows are sorted alphabetically by the row key as they are stored. For this reason, the design of the row key is very important. The goal is to store data in such a way that related rows are near each other. A common row key pattern is a website domain. If your row keys are domains, you should probably store them in reverse (org.apache.www, org.apache.mail, org.apache.jira). This way, all of the Apache domains are near each other in the table, rather than being spread out based on the first letter of the subdomain. Within a table, data is stored according to its row. Rows are identified uniquely by their row key. Row keys do not have a data type and are always treated as a byte[ ] ( byte array).
- Column – A column in HBase consists of a column family and a column qualifier, which are delimited by a : (colon) character.
- Column Family – Column families physically colocate a set of columns and their values, often for performance reasons. Each column family has a set of storage properties, such as whether its values should be cached in memory, how its data is compressed or its row keys are encoded, and others. Each row in a table has the same column families, though a given row might not store anything in a given column family. Data within a row is grouped by column family. Column families also impact the physical arrangement of data stored in HBase. For this reason, they must be defined up front and are not easily modified. Every row in a table has the same column families, although a row need not store data in all its families. Column families are Strings and composed of characters that are safe for use in a file system path.
- Column Qualifier – A column qualifier is added to a column family to provide the index for a given piece of data. Given a column family content, a column qualifier might be content:html, and another might be content:pdf. Though column families are fixed at table creation, column qualifiers are mutable and may differ greatly between rows. Data within a column family is addressed via its column qualifier, or simply, column. Column qualifiers need not be specified in advance. Column qualifiers need not be consistent between rows. Like row keys, column qualifiers do not have a data type and are always treated as a byte[ ].
- Cell – A cell is a combination of row, column family, and column qualifier, and contains a value and a timestamp, which represents the value’s version. A combination of row key, column family, and column qualifier uniquely identifies a cell. The data stored in a cell is referred to as that cell’s value. Values also do not have a data type and are always treated as a byte[ ].
- Timestamp – A timestamp is written alongside each value, and is the identifier for a given version of a value. By default, the timestamp represents the time on the RegionServer when the data was written, but you can specify a different timestamp value when you put data into the cell. Values within a cell are versioned. Versions are identified by their version number, which by default is the timestamp of when the cell was written. If a timestamp is not specified during a write, the current timestamp is used. If the timestamp is not specified for a read, the latest one is returned. The number of cell value versions retained by HBase is configured for each column family. The default number of cell versions is three.
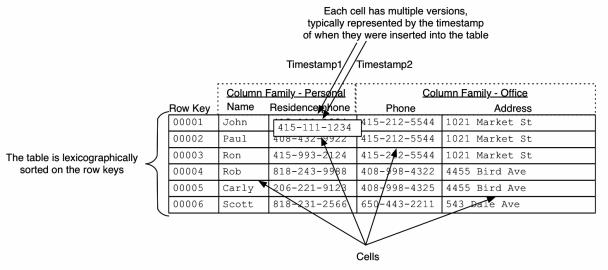
These concepts are also exposed via the API to clients. HBase’s API for data manipulation consists of three primary methods: Get, Put, and Scan. Gets and Puts are specific to particular rows and need the row key to be provided. Scans are done over a range of rows. The range could be defined by a start and stop row key or could be the entire table if no start and stop row keys are defined. Sometimes, it’s easier to understand the data model as a multidimensional map. The first row from the table in Figure 1 has been represented as a multidimensional map in figure below.
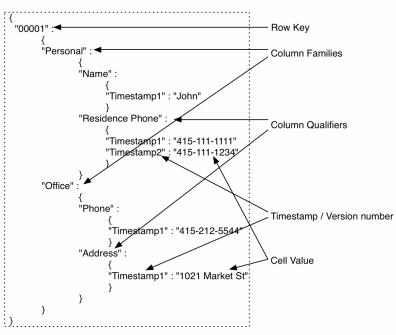
The row key maps to a list of column families, which map to a list of column qualifiers, which map to a list of timestamps, each of which map to a value, i. e. , the cell itself. If you were to retrieve the item that the row key maps to, you’d get data from all the columns back. If you were to retrieve the item that a particular column family maps to, you’d get back all the column qualifiers and the associated maps. If you were to retrieve the item that a particular column qualifier maps to, you’d get all the timestamps and the associated values. HBase optimizes for typical patterns and returns only the latest version by default. You can request multiple versions as a part of your query. Row keys are the equivalent of primary keys in relational database tables. You cannot choose to change which column in an HBase table will be the row key after the table has been set up. In other words, the column Name in the Personal column family cannot be chosen to become the row key after the data has been put into the table.
As mentioned earlier, there are various ways of describing this data model. You can view the same thing as if it’s a key-value store (as shown in figure below), where the key is the row key and the value is the rest of the data in a column. Given that the row key is the only way to address a row, that seems befitting. You can also consider HBase to be a key-value store where the key is defined as row key, column family, column qualifier, timestamp, and the value is the actual data stored in the cell. When we go into the details of the underlying storage later, you’ll see that if you want to read a particular cell from a given row, you end up reading a chunk of data that contains that cell and possibly other cells as well. This representation is also how the KeyValue objects in the HBase API and internals are represented. Key is formed by [row key, column family, column qualifier, timestamp] and Value is the contents of the cell.

Physical View
Although at a conceptual level tables may be viewed as a sparse set of rows, they are physically stored by column family. A new column qualifier (column_family:column_qualifier) can be added to an existing column family at any time.
ColumnFamily anchor
| Row Key | Time Stamp | Column Family anchor |
| “com.cnn.www” | t9 | anchor:cnnsi.com = “CNN” |
| “com.cnn.www” | t8 | anchor:my.look.ca = “CNN.com” |
ColumnFamily contents
| Row Key | Time Stamp | ColumnFamily contents: |
| “com.cnn.www” | t6 | contents:html = “<html>…” |
| “com.cnn.www” | t5 | contents:html = “<html>…” |
| “com.cnn.www” | t3 | contents:html = “<html>…” |
The empty cells shown in the conceptual view are not stored at all. Thus a request for the value of the contents:html column at time stamp t8 would return no value. Similarly, a request for an anchor:my.look.ca value at time stamp t9 would return no value. However, if no timestamp is supplied, the most recent value for a particular column would be returned. Given multiple versions, the most recent is also the first one found, since timestamps are stored in descending order. Thus a request for the values of all columns in the row com.cnn.www if no timestamp is specified would be: the value of contents:html from timestamp t6, the value of anchor:cnnsi.com from timestamp t9, the value of anchor:my.look.ca from timestamp t8.
HBase Run Modes
HBase has two run modes: standalone and distributed. Out of the box, HBase runs in standalone mode. Whatever your mode, you will need to configure HBase by editing files in the HBase conf directory. At a minimum, you must edit conf/hbase-env.sh to tell HBase which java to use. In this file you set HBase environment variables such as the heapsize and other options for the JVM, the preferred location for log files, etc. Set JAVA_HOME to point at the root of your java install.
- Standalone HBase – This is the default mode. Standalone mode is what is described in the quickstart section. In standalone mode, HBase does not use HDFS, it uses the local filesystem instead, and it runs all HBase daemons and a local ZooKeeper all up in the same JVM. Zookeeper binds to a well known port so clients may talk to HBase.
- Distributed – Distributed mode can be subdivided into distributed but all daemons run on a single node or pseudo-distributed — and fully-distributed where the daemons are spread across all nodes in the cluster. The pseudo-distributed vs. fully-distributed nomenclature comes from Hadoop. Pseudo-distributed mode can run against the local filesystem or it can run against an instance of the Hadoop Distributed File System (HDFS). Fully-distributed mode can ONLY run on HDFS.
