
Certify and Increase Opportunity.
Be
Govt. Certified Linux Administrator
All the files are grouped together in the directory structure. The file-system is arranged in a hierarchical structure, like an inverted tree. The top of the hierarchy is traditionally called root (written as a slash / )
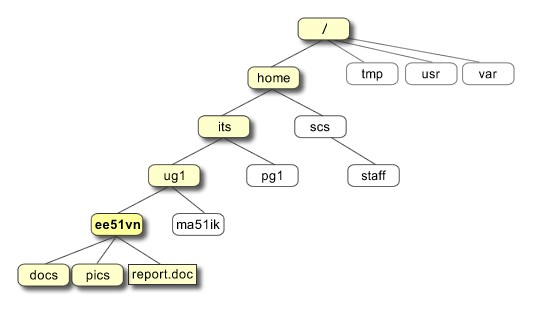

In the diagram above, we see that the home directory of the undergraduate student “ee51vn” contains two sub-directories (docs and pics) and a file called report.doc. The full path to the file report.doc is “/home/its/ug1/ee51vn/report.doc”
Slashes are used to separate directory names in Linux. Physical drives are handled differently than DOS. The /usr directory could be on a separate hard disk, or /mnt might contain a folder named /storage that is actually a drive from another computer. Some of the more common directories found on a Linux system are
- / Represents the root directory.
- /bin Contains common Linux user commands, such as ls, sort, date, and chmod.
- /dev Contains files representing access points to devices on your systems. These can include floppy disks, hard disks, and CD-ROMs.
- /etc Contains administrative configuration files, the passwd file, and the shadow file.
- /home Contains user home directories.
- /mnt Provides a location for mounting devices, such as CD-ROMs and USB drives.
- /sbin Contains administrative commands and daemon processes.
- /usr Contains user documentation, graphical files, libraries, as well as a variety of other user and administrative commands and files.
Directories and files on a Linux system are set up so that access can be controlled. When you log in to the system, you are identified by a user account. In addition to your user account, you might belong to a group or groups. Therefore, files can have permissions set for a user, a group, or others. For example, Red Hat Linux supports three default groups: super users, system users, and normal users. Access for each of these groups has three options – Read, Write and Execute.
To see the current permissions, owner, and group for a file or directory, type the ls -l command. This will display the contents of the directory you are in with the privileges for the user, group, and all others. For example, the list of a file called demofile and the directory demodir would resemble the following
drwxr-xr-x 2 abc users 32768 Nov 20 00:31 demodir
-rw-r–r– 1 abc users 4108 Nov 16 11:21 demofile
The permissions are listed in the first column. The first letter is whether the item is a directory or a file. If the first letter is d, the item is a directory, as in the first item listed previously, demodir. For the file demofile, the first letter is -. The next nine characters denote access and take the following form, rwx|rwx|rwx. The first three list the access rights of the user, so for demodir, the user has read, write, and execute privileges. The next three bits denote the group rights; therefore, the group has read and execute privileges for the demodir folder. Finally, the last three bits specify the access all others have to the demodir folder. In this case, they have read and execute privileges. The third column, abc, specifies the owner of the file/directory, and the fourth column, users, is the name of the group for the file/directory. The only one who can modify or delete any file in this directory is the owner abc.
The chmod command is used by a file owner or administrator to change the definition of access permissions to a file or set of files. Chmod can be used in symbolic and absolute modes. Symbolic deals with symbols such as rwx, whereas absolute deals with octal values. For each of the three sets of permission on a fileread, write, and executeread is assigned the number 4, write is assigned the number 2, and execute is assigned the number 1. To make sure that permissions are wide open for yourself, the group, and all users, the command would be chmod 777 demofile.
Access for users and system processes are assigned a User ID (UID) and a Group ID (GID). Groups are the logical grouping of users that have similar requirements. This information is contained in the /etc/passwd file. An example is listed below
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:
daemon:x:2:2:daemon:/sbin:
adm:x:3:4:adm:/var/adm:
lp:x:4:7:lp:/var/spool/lpd:
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:
news:x:9:13:news:/var/spool/news:
operator:x:11:0:operator:/root:
gopher:x:13:30:gopher:/usr/lib/gopher-data:
ftp:x:14:50:FTP User:/home/ftp:
xfs:x:43:43:X Font Server:/etc/X11/fs:/bin/false
named:x:25:25:Named:/var/named:/bin/false
abc:x:503:503:Mike:/home/mg:/bin/bash
You will notice that root is the first account in the list. Root is always assigned the UID 0 and the GID 0. Other special users and accounts associated with services and daemons are listed after root and have values below 100. Red Hat starts regular users at a UID of 500. The fields are denoted by the colons.
- The username is the first field. Initial capitalization is not used to avoid upper/lowercase confusion.
- The second field holds the encrypted password. The field is marked by an x in this case; that is because this particular Linux system is using shadow passwords, which are held in /etc/shadow. The shadow file is used to increase security and is located at /etc/shadow.
- The third field is the UID. ABC’s UID is 503 and any file abc owns or creates will have this number associated with it.
- The fourth field is the GID. ABC’s GID is 503. The GID and UID are the same.
- The fifth field is the user description. This field holds descriptive information about the user. It can sometimes contain phone numbers, mail stops, or some other contact information. This is not a good idea as it can be reported by the finger utility.
- The sixth field is the User’s Home Directory. When the user is authenticated, the login program uses this field to define the user’s $HOME variable. By default, in all Linux distributions, the user’s home directory will be assumed to be /home/username.
- The seventh and final field is the User’s Login Shell. When the user is authenticated, the login program also sets the users $SHELL variable to this field. By default, in all Linux distributions, a new user’s login shell will be set to /bin/bash, the Bourne Again Shell.
Adding users to Linux is done by the useradd command. Files such as passwd are world readable, the shadow file is only readable by root. If an attacker can gain access to the root account, he has essentially taken control of the computer from you. For this reason, the root account must be protected at the highest level. The Substitute User (SU) command will allow to perform duties as a different user than the one you are logged in as. The command is simply su <username>.
In order to use disks to store files under Linux, a file system must be written onto the disk. Linux supports several different types of file systems, but ext2fs (Second Extended File System) is the standard. Linux also supports MS-DOS/Windows 95/98/NT, Mac OS HFS, OS/2, NFS, and other file systems. Linux supports multiple partitions. Each partition is accessed through a node of the directory structure and can be any supported partition type.
Each native Linux file system partition has an inode table, which contains one record for each file stored within the partition. Each file is uniquely identified within the file system by its inode number, and each file has a single inode table entry. The inode table entry holds all attributes of a file, such as file size, user, group, permissions, etc. Directories map names into inode numbers but do not store file attributes. A directory can have more than one name referencing an inode number.
Files and directories have attributes that are stored in the inode table. The combined attributes of permission and file ownership provide a sophisticated file access mechanism.
The full directory tree is intended to be breakable into smaller parts, each capable of being on its own disk or partition, to accommodate to disk size limits and to ease backup and other system administration tasks. The major parts are the root (/ ), /usr , /var , and /home filesystems. Each part has a different purpose. The directory tree has been designed so that it works well in a network of Linux machines which may share some parts of the filesystems over a read−only device (e.g., a CD−ROM), or over the network with NFS.
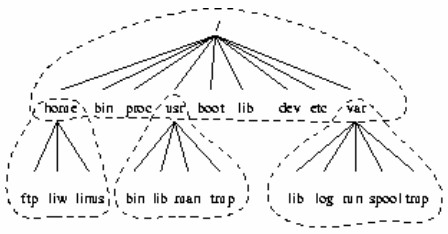

- The root filesystem is specific for each machine (it is generally stored on a local disk, although it could be a ramdisk or network drive as well) and contains the files that are necessary for booting the system up, and to bring it up to such a state that the other filesystems may be mounted. The contents of the root filesystem will therefore be sufficient for the single user state. It will also contain tools for fixing a broken system, and for recovering lost files from backups.
- The /usr filesystem contains all commands, libraries, manual pages, and other unchanging files needed during normal operation. No files in /usr should be specific for any given machine, nor should they be modified during normal use. This allows the files to be shared over the network, which can be cost−effective since it saves disk space (there can easily be hundreds of megabytes, increasingly multiple gigabytes in /usr). It can make administration easier (only the master /usr needs to be changed when updating an application, not each machine separately) to have /usr network mounted. Even if the filesystem is on a local disk, it could be mounted read−only, to lessen the chance of filesystem corruption during a crash.
- The /var filesystem contains files that change, such as spool directories (for mail, news, printers, etc), log files, formatted manual pages, and temporary files. Traditionally everything in /var has been somewhere below /usr , but that made it impossible to mount /usr read−
- The /home filesystem contains the users’ home directories, i.e., all the real data on the system. Separating home directories to their own directory tree or filesystem makes backups easier; the other parts often do not have to be backed up, or at least not as often as they seldom change. A big /home might have to be broken across several filesystems, which requires adding an extra naming level below /home, for example /home/students and /home/staff.
Although the different parts have been called filesystems above, there is no requirement that they actually be on separate filesystems. They could easily be kept in a single one if the system is a small single−user system and the user wants to keep things simple. The directory tree might also be divided into filesystems differently, depending on how large the disks are, and how space is allocated for various purposes. The important part, though, is that all the standard names work; even if, say, /var and /usr are actually on the same partition, the names /usr/lib/libc.a and /var/log/messages must work, for example by moving files below /var into /usr/var, and making /var a symlink to /usr/var.
The Unix filesystem structure groups files according to purpose, i.e., all commands are in one place, all data files in another, documentation in a third, and so on. An alternative would be to group files according to the program they belong to, i.e., all Emacs files would be in one directory, all TeX in another, and so on. The problem with the latter approach is that it makes it difficult to share files (the program directory often contains both static and sharable and changing and non−sharable files), and sometimes to even find the files (e.g., manual pages in a huge number of places, and making the manual page programs find all of them is a maintenance nightmare).
inode
When a file is created, it is assigned both a name and an inode number, which is an integer that is unique within the filesystem. Both the file names and their corresponding inode numbers are stored as entries in the directory that appears to the user to contain the files. That is, the directory associates file names with inodes.
Whenever a user or a program refers to a file by name, the operating system uses that name to look up the corresponding inode, which then enables the system to obtain the information it needs about the file to perform further operations. That is, a file name in a Unix-like operating system is merely an entry in a table with inode numbers, rather than being associated directly with a file (in contrast to other operating systems such as the Microsoft Windows systems). The inode numbers and their corresponding inodes are held in inode tables, which are stored in strategic locations in a filesystem, including near its beginning.
This detaching of a file’s name from its other metadata is what allows the system to implement hard links and thus have multiple names for any file. A hard link is an entry in a directory that contains a pointer directly to the inode bearing the file’s metadata. When a new hard link to a file is created, both links share the same inode number because the link is only a pointer, not a copy of the file.
The concept of inodes is particularly important to the recovery of damaged filesystems. When parts of the inode are lost, they appear in the lost+found directory within the partition in which they once existed.
Whereas a file contains only its own content and a directory holds only the names of the files that appear to the user to be contained in it and their inode numbers, an inode contains all the other information describing a file. This metadata includes (1) the size of the file (in bytes) and its physical location (i.e., the addresses of the blocks of storage containing the file’s data on a HDD), (2) the file’s owner and group, (3) the file’s access permissions (i.e., which users are permitted to read, write and/or execute the file), (4) timestamps telling when the inode was created, last modified and last accessed and (5) a reference count telling how many hard links point to the inode.
The operating system obtains a file’s inode number and information in the inode through the use of the system call named stat. A system call is a request in a Unix-like operating system by an active process for a service performed by the kernel (i.e., the core of the operating system), such as input/output (I/O) or process creation. System calls can also be viewed as clearly-defined, direct entry points into the kernel through which programs request services from it. A process is an instance of a program in execution, and an active process, is one which is currently progressing in the CPU (central processing unit).
A file’s inode number can easily be found by using the ls command, which by default lists the objects (i.e., files, links and directories) in the current directory (i.e., the directory in which the user is currently working), with its -i option. Thus, for example, the following will show the name of each object in the current directory together with its inode number:
- ls –i — Additional information can be obtained about the inodes on a system by using the df command. This command by default shows the names and sizes of each mounted (i.e., logically connected to the main filesystem) filesystem as well as how much of each is used and unused. One of df’s most useful options is -h, which formats the information in human readable form (i.e., in terms of kilobytes, megabytes and gigabytes). Thus the following provides a nice display of both the currently available space and the used space for each filesystem or partition:
- df –h — df’s -i option instructs it to supply information about inodes on each filesystem rather than about available space. Specifically, it tells df to return for each mounted filesystem the total number of inodes, the number of free inodes, the number of used inodes and the percentage of inodes used. This option can be used together with the -h option as follows to make the output easier to read:
- df –hi — The exact story behind the creation of the term inode has been lost, but it is very likely that the i originally stood for index and/or information.
Superblocks
The first piece of information read from a disk is its superblock. This small data structure reveals several key pieces of information, including the disk’s geometry, the amount of available space, and, most importantly, the location of the first i-node. Without a superblock, an on-disk file system is useless.
Multiple copies of this data structure are scattered all over the disk to provide backup in case the first one is damaged. Under Linux’s ext2 file system, a superblock is placed after every group of blocks, which contains i-nodes and data. One group consists of 8192 blocks; thus, the first redundant superblock is at 8193, the second at 16,385, and so on. The designers of most Linux file systems intelligently included this superblock redundancy into the file system design.
The root filesystem
The root filesystem should generally be small, since it contains very critical files and a small, infrequently modified filesystem has a better chance of not getting corrupted. A corrupted root filesystem will generally mean that the system becomes unbootable except with special measures (e.g., from a floppy), so you don’t want to risk it.
The root directory generally doesn’t contain any files, except perhaps on older systems where the standard boot image for the system, usually called /vmlinuz was kept there. (Most distributions have moved those files the /boot directory. Otherwise, all files are kept in subdirectories under the root filesystem –
- /bin – Commands needed during bootup that might be used by normal users (probably after bootup).
- /sbin – Like /bin, but the commands are not intended for normal users, although they may use them if necessary and allowed. /sbin is not usually in the default path of normal users, but will be in root’s default path.
- /etc – Configuration files specific to the machine.
- /root – The home directory for user root. This is usually not accessible to other users on the system
- /lib – Shared libraries needed by the programs on the root filesystem.
- /lib/modules – Loadable kernel modules, especially those that are needed to boot the system when recovering from disasters (e.g., network and filesystem drivers).
- /dev – Device files. These are special files that help the user interface with the various devices on the system.
- /tmp – Temporary files. As the name suggests, programs running often store temporary files in here.
- /boot – Files used by the bootstrap loader, e.g., LILO or GRUB. Kernel images are often kept here instead of in the root directory. If there are many kernel images, the directory can easily grow rather big, and it might be better to keep it in a separate filesystem. Another reason would be to make sure the kernel images are within the first 1024 cylinders of an IDE disk. This 1024 cylinder limit is no longer true in most cases. With modern BIOSes and later versions of LILO (the LInux LOader) the 1024 cylinder limit can be passed with logical block addressing (LBA).
- /mnt – Mount point for temporary mounts by the system administrator. Programs aren’t supposed to mount on /mnt automatically. /mnt might be divided into subdirectories (e.g., /mnt/dosa might be the floppy drive using an MS−DOS filesystem, and /mnt/exta might be the same with an ext2 filesystem).
- /proc, /usr, /var, /home – Mount points for the other filesystems. Although /proc does not reside on any disk in reality it is still mentioned here.
The /etc directory
The /etc maintains a lot of files. Some of them are described below. For others, you should determine which program they belong to and read the manual page for that program.
- /etc/rc or /etc/rc.d or /etc/rc?.d – Scripts or directories of scripts to run at startup or when changing the run level.
- /etc/passwd – The user database, with fields giving the username, real name, home directory, and other information about each user. The format is documented in the passwd manual page.
- /etc/shadow – /etc/shadow is an encrypted file the holds user passwords.
- /etc/fdprm – Floppy disk parameter table. Describes what different floppy disk formats look like. Used by setfdprm .
- /etc/fstab – Lists the filesystems mounted automatically at startup by the mount −a command (in /etc/rc or equivalent startup file). Under Linux, also contains information about swap areas used automatically by swapon −a .
- /etc/group – Similar to /etc/passwd, but describes groups instead of users.
- /etc/inittab – Configuration file for init.
- /etc/issue – Output by getty before the login prompt. Usually contains a short description or welcoming message to the system. The contents are up to the system administrator.
- /etc/magic – The configuration file for file. Contains the descriptions of various file formats based on which file guesses the type of the file.
- /etc/motd – The message of the day, automatically output after a successful login. Contents are up to the system administrator. Often used for getting information to every user, such as warnings about planned downtimes.
- /etc/mtab – List of currently mounted filesystems. Initially set up by the bootup scripts, and updated automatically by the mount command. Used when a list of mounted filesystems is needed, e.g., by the df command.
- /etc/login.defs – Configuration file for the login command.
- /etc/printcap – Like /etc/termcap/etc/printcap , but intended for printers. However it uses different syntax.
- /etc/profile, /etc/bash.rc, /etc/csh.cshrc – Files executed at login or startup time by the Bourne, BASH , or C shells. These allow the system administrator to set global defaults for all users. Users can also create individual copies of these in their home directory to personalize their environment.
- /etc/securetty – Identifies secure terminals, i.e., the terminals from which root is allowed to log in. Typically only the virtual consoles are listed, so that it becomes impossible (or at least harder) to gain superuser privileges by breaking into a system over a modem or a network. Do not allow root logins over a network. Prefer to log in as an unprivileged user and use su or sudo to gain root privileges.
- /etc/shells – Lists trusted shells. The chsh command allows users to change their login shell only to shells listed in this file. ftpd, is the server process that provides FTP services for a machine, will check that the user’s shell is listed in /etc/shells and will not let people log in unless the shell is listed there.
- /etc/termcap – The terminal capability database. Describes by what “escape sequences” various terminals can be controlled. Programs are written so that instead of directly outputting an escape sequence that only works on a particular brand of terminal, they look up the correct sequence to do whatever it is they want to do in /etc/termcap. As a result most programs work with most kinds of terminals.
The /dev directory
The /dev directory contains the special device files for all the devices. The device files are created during installation, and later with the /dev/MAKEDEV script. The /dev/MAKEDEV.local is a script written by the system administrator that creates local−only device files or links (i.e. those that are not part of the standard MAKEDEV, such as device files for some non−standard device driver).
This list which follows is by no means exhaustive or as detailed as it could be. Many of these device files will need support compiled into your kernel for the hardware. Read the kernel documentation to find details of any particular device.
- /dev/dsp – Digital Signal Processor. Basically this forms the interface between software which produces sound and your soundcard. It is a character device on major node 14 and minor 3.
- /dev/fd0 – The first floppy drive. If you are lucky enough to have several drives then they will be numbered sequentially. It is a character device on major node 2 and minor 0.
- /dev/fb0 – The first framebuffer device. A framebuffer is an abstraction layer between software and graphics hardware. This means that applications do not need to know about what kind of hardware you have but merely how to communicate with the framebuffer driver’s API (Application Programming Interface) which is well defined and standardized. The framebuffer is a character device and is on major node 29 and minor 0.
- /dev/hda – /dev/hda is the master IDE drive on the primary IDE controller. /dev/hdb the slave drive on the
- primary controller. /dev/hdc , and /dev/hdd are the master and slave devices on the secondary controller respectively. Each disk is divided into partitions. Partitions 1−4 are primary partitions and partitions 5 and above are logical partitions inside extended partitions. Therefore the device file which references each partition is made up of several parts. For example /dev/hdc9 references partition 9 (a logical partition inside an extended partition type) on the master IDE drive on the secondary IDE controller. The major and minor node numbers are somewhat complex. For the first IDE controller all partitions are block devices on major node 3. The master drive hda is at minor 0 and the slave drive hdb is at minor 64. For each partition inside the drive add the partition number to the minor node number for the drive. For example /dev/hdb5 is major 3, minor 69 (64 + 5 = 69). Drives on the secondary interface are handled the same way, but with major node 22.
- /dev/ht0 – The first IDE tape drive. Subsequent drives are numbered ht1 etc. They are character devices on major node 37 and start at minor node 0 for ht0 1 for ht1 etc.
- /dev/js0 – The first analogue joystick. Subsequent joysticks are numbered js1, js2 etc. Digital joysticks are called djs0, djs1 and so on. They are character devices on major node 15. The analogue joysticks start at minor node 0 and go up to 127 (more than enough for even the most fanatic gamer). Digital joysticks start at minor node 128.
- /dev/lp0 – The first parallel printer device. Subsequent printers are numbered lp1, lp2 etc. They are character devices on major mode 6 and minor nodes starting at 0 and numbered sequentially.
- /dev/loop0 – The first loopback device. Loopback devices are used for mounting filesystems which are not located on other block devices such as disks. For example if you wish to mount an iso9660 CD ROM image without burning it to CD then you need to use a loopback device to do so. This is usually transparent to the user and is handled by the mount command. The loopback devices are block devices on major node 7 and with minor nodes starting at 0 and numbered sequentially.
- /dev/md0 – First metadisk group. Metadisks are related to RAID (Redundant Array of Independent Disks) devices. Metadisk devices are block devices on major node 9 with minor nodes starting at 0 and numbered sequentially.
- /dev/mixer – This is part of the OSS (Open Sound System) driver. It is a character device on major node 14, minor node 0.
- /dev/null – The bit bucket. A black hole where you can send data for it never to be seen again. Anything sent to /dev/null will disappear. This can be useful if, for example, you wish to run a command but not have any feedback appear on the terminal. It is a character device on major node 1 and minor node 3.
- /dev/psaux – The PS/2 mouse port. This is a character device on major node 10, minor node 1.
- /dev/pda – Parallel port IDE disks. These are named similarly to disks on the internal IDE controllers (/dev/hd*). They are block devices on major node 45. Minor nodes need slightly more explanation here. The first device is /dev/pda and it is on minor node 0. Partitions on this device are found by adding the partition number to the minor number for the device. Each device is limited to 15 partitions each rather than 63 (the limit for internal IDE disks). /dev/pdb minor nodes start at 16, /dev/pdc at 32 and /dev/pdd at 48. So for example the minor node number for /dev/pdc6 would be 38 (32 + 6 = 38). This scheme limits you to 4 parallel disks of 15 partitions each.
- /dev/pcd0 – Parallel port CD ROM drives. These are numbered from 0 onwards. All are block devices on major node 46. /dev/pcd0 is on minor node 0 with subsequent drives being on minor nodes 1, 2, 3 etc.
- /dev/pt0 – Parallel port tape devices. Tapes do not have partitions so these are just numbered sequentially. They are character devices on major node 96. The minor node numbers start from 0 for /dev/pt0, 1 for /dev/pt1, and so on.
- /dev/parport0 – The raw parallel ports. Most devices which are attached to parallel ports have their own drivers. This is a device to access the port directly. It is a character device on major node 99 with minor node 0. Subsequent devices after the first are numbered sequentially incrementing the minor node.
- /dev/random or /dev/urandom – These are kernel random number generators. /dev/random is a non−deterministic generator which means that the value of the next number cannot be guessed from the preceding ones. It uses the entropy of the system hardware to generate numbers. When it has no more entropy to use then it must wait until it has collected more before it will allow any more numbers to be read from it. /dev/urandom works similarly. Initially it also uses the entropy of the system hardware, but when there is no more entropy to use it will continue to return numbers using a pseudo random number generating formula. This is considered to be less secure for vital purposes such as cryptographic key pair generation. If security is your overriding concern then use /dev/random, if speed is more important then /dev/urandom works fine. They are character devices on major node 1 with minor nodes 8 for /dev/random and 9 for /dev/urandom.
- /dev/sda – The first SCSI drive on the first SCSI bus. The following drives are named similar to IDE drives. /dev/sdb is the second SCSI drive, /dev/sdc is the third SCSI drive, and so forth.
- /dev/ttyS0 – The first serial port. Many times this it the port used to connect an external modem to your system.
- /dev/zero – This is a simple way of getting many 0s. Every time you read from this device it will return 0. This can be useful sometimes, for example when you want a file of fixed length but don’t really care what it contains. It is a character device on major node 1 and minor node 5.
The /usr filesystem
The /usr filesystem is often large, since all programs are installed there. All files in /usr usually come from a Linux distribution; locally installed programs and other stuff goes below /usr/local. This makes it possible to update the system from a new version of the distribution, or even a completely new distribution, without having to install all programs again. Some of the subdirectories of /usr are listed below (some of the less important directories have been dropped).
- /usr/X11R6 – The X Window System, all files. To simplify the development and installation of X, the X files have not been integrated into the rest of the system. There is a directory tree below /usr/X11R6 similar to that below /usr itself.
- /usr/bin -Almost all user commands. Some commands are in /bin or in /usr/local/bin.
- /usr/sbin -System administration commands that are not needed on the root filesystem, e.g., most server programs.
- /usr/share/man, /usr/share/info, /usr/share/doc – Manual pages, GNU Info documents, and miscellaneous other documentation files, respectively.
- /usr/include – Header files for the C programming language. This should actually be below /usr/lib for consistency, but the tradition is overwhelmingly in support for this name.
- /usr/lib – Unchanging data files for programs and subsystems, including some site−wide configuration files. The name lib comes from library; originally libraries of programming subroutines were stored in /usr/lib.
- /usr/local – The place for locally installed software and other files. Distributions may not install anything in here. It is reserved solely for the use of the local administrator. This way he can be absolutely certain that no updates or upgrades to his distribution will overwrite any extra software he has installed locally.
The /var filesystem
The /var contains data that is changed when the system is running normally. It is specific for each system, i.e., not shared over the network with other computers.
- /var/cache/man – A cache for man pages that are formatted on demand. The source for manual pages is usually stored in /usr/share/man/man?/ (where ? is the manual section 7); some manual pages might come with a pre−formatted version, which might be stored in /usr/share/man/cat* . Other manual pages need to be formatted when they are first viewed; the formatted version is then stored in /var/cache/man so that the next person to view the same page won’t have to wait for it to be formatted.
- /var/games – Any variable data belonging to games in /usr should be placed here. This is in case /usr is mounted read only.
- /var/lib – Files that change while the system is running normally.
- /var/local – Variable data for programs that are installed in /usr/local (i.e., programs that have been installed by the system administrator). Note that even locally installed programs should use the other /var directories if they are appropriate, e.g., /var/lock.
- /var/lock – Lock files. Many programs follow a convention to create a lock file in /var/lock to indicate that they are using a particular device or file. Other programs will notice the lock file and won’t attempt to use the device or file.
- /var/log – Log files from various programs, especially login(/var/log/wtmp, which logs all logins and logouts into the system) and syslog(/var/log/messages, where all kernel and system program message are usually stored). Files in /var/log can often grow indefinitely, and may require cleaning at regular intervals.
- /var/mail – This is the FHS approved location for user mailbox files. Depending on how far your distribution has gone towards FHS compliance, these files may still be held in /var/spool/mail.
- /var/run – Files that contain information about the system that is valid until the system is next booted. For example, /var/run/utmp contains information about people currently logged in.
- /var/spool – Directories for news, printer queues, and other queued work. Each different spool has its own subdirectory below /var/spool, e.g., the news spool is in /var/spool/news . Note that some installations which are not fully compliant with the latest version of the FHS may have user mailboxes under /var/spool/mail.
- /var/tmp – Temporary files that are large or that need to exist for a longer time than what is allowed for /tmp . (Although the system administrator might not allow very old files in /var/tmp either.)
The /proc filesystem
The /proc filesystem contains a illusionary filesystem. It does not exist on a disk. Instead, the kernel creates it in memory. It is used to provide information about the system (originally about processes, hence the name). Some of the more important files and directories are explained below.
- /proc/1 – A directory with information about process number 1. Each process has a directory below /proc with the name being its process identification number.
- /proc/cpuinfo – Information about the processor, such as its type, make, model, and performance.
- /proc/devices – List of device drivers configured into the currently running kernel.
- /proc/dma – Shows which DMA channels are being used at the moment.
- /proc/filesystems – Filesystems configured into the kernel.
- /proc/interrupts – Shows which interrupts are in use, and how many of each there have been.
- /proc/ioports – Which I/O ports are in use at the moment.
- /proc/kcore – An image of the physical memory of the system. This is exactly the same size as your physical memory, but does not really take up that much memory; it is generated on the fly as programs access it. (Remember: unless you copy it elsewhere, nothing under /proc takes up any disk space at all.)
- /proc/kmsg – Messages output by the kernel. These are also routed to syslog.
- /proc/ksyms – Symbol table for the kernel.
- /proc/loadavg – The `load average’ of the system; three meaningless indicators of how much work the system has to do at the moment.
- /proc/meminfo – Information about memory usage, both physical and swap.
- /proc/modules – Which kernel modules are loaded at the moment.
- /proc/net – Status information about network protocols.
- /proc/self – A symbolic link to the process directory of the program that is looking at /proc. When two processes look at /proc, they get different links. This is mainly a convenience to make it easier for programs to get at their process directory.
- /proc/stat – Various statistics about the system, such as the number of page faults since the system was booted.
- /proc/uptime – The time the system has been up.
- /proc/version – The kernel version.
Note that while the above files tend to be easily readable text files, they can sometimes be formatted in a way that is not easily digestible. There are many commands that do little more than read the above files and format them for easier understanding. For example, the freeprogram reads /proc/meminfo converts the amounts given in bytes to kilobytes (and adds a little more information, as well).
Apply for Linux Administration Certification Now!!
http://www.vskills.in/certification/Certified-Linux-Administrator