A workflow consists of an orchestrated and repeatable pattern of business activity enabled by the systematic organization of resources into processes that transform materials, provide services, or process information.
A workflow management system (WfMS) provides an infrastructure for the set-up, performance and monitoring of a defined sequence of tasks, arranged as a workflow.
Workflow Management System (WMS) is a piece of software that provides an infrastructure to setup, execute, and monitor scientific workflows. In other words, the WMS provide an environment where in silico experiments can be defined and executed.
An important function of an WMS during the workflow execution, or enactment, is the coordination of operation of individual components that constitute the workflow – the process also often referred to as orchestration.
Oozie is a workflow scheduler system to manage Apache Hadoop jobs. Oozie Workflow jobs are Directed Acyclical Graphs (DAGs) of actions. Oozie Coordinator jobs are recurrent Oozie Workflow jobs triggered by time (frequency) and data availabilty. Oozie is integrated with the rest of the Hadoop stack supporting several types of Hadoop jobs out of the box (such as Java map-reduce, Streaming map-reduce, Pig, Hive, Sqoop and Distcp) as well as system specific jobs (such as Java programs and shell scripts). Oozie is a scalable, reliable and extensible system.
Oozie drives the MapReduce jobs and Hadoop Distributed File System (HDFS) operations. Oozie can also orchestrate most of the common higher-level tools such as Pig, Hive, Sqoop, and DistCp. It can also be extended to support any custom Hadoop job written in any language. Oozie can handle Hadoop components and the execution of any other non-Hadoop job like a Java class, or a shell script.
Oozie is an orchestration system for Hadoop jobs. Oozie runs multistage Hadoop jobs as a single job or an Oozie job. Oozie jobs can be configured to run on demand or periodically. Oozie jobs running on demand are called worklow jobs. Oozie jobs running periodically are called coordinator jobs. There is also a third type of Oozie job called bundle jobs. A bundle job is a collection of coordinator jobs managed as a single job.
Oozie is a Java Web-Application that runs in a Java servlet-container (Tomcat) and uses a database to store
- Definitions of Oozie jobs – workflow/coordinator/bundle
- Currently running workflow instances, including instance states and variables
Oozie works with HSQL, Derby, MySQL, Oracle or PostgreSQL databases. By default, Oozie is configured to use Embedded Derby. Oozie bundles the JDBC drivers for HSQL, Embedded Derby and PostgreSQL.
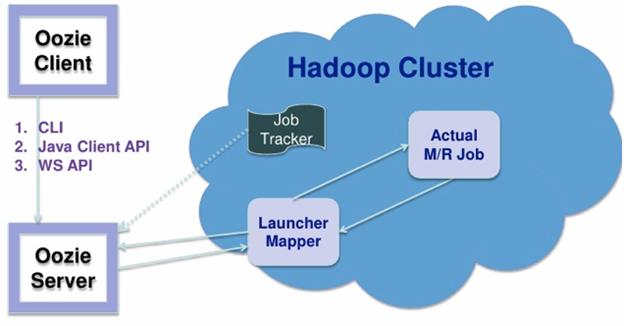
The architecture of Oozie is as
Installation
Installation involves installing the servew and client, as
Server Installation
System Requirements
- Unix (tested in Linux and Mac OS X)
- Java 1.6+
- Apache Hadoop (tested with 1.0.0 & 0.23.1)
- ExtJS 2.2 library (optional, to enable Oozie webconsole)
The Java 1.6+ bin directory should be in the command path. Oozie ignores any set value for OOZIE_HOME , Oozie computes its home automatically.
- Build an Oozie binary distribution
- Download a Hadoop binary distribution
- Download ExtJS library (it must be version 2.2)
The ExtJS library is not bundled with Oozie because it uses a different license. It is recommended to use a Oozie Unix user for the Oozie server. Expand the Oozie distribution tar.gz . Expand the Hadoop distribution tar.gz (as the Oozie Unix user). Configure the Hadoop cluster with proxyuser for the Oozie process. The following two properties are required in Hadoop core-site.xml:
<!– OOZIE –>
<property>
<name>hadoop.proxyuser.[OOZIE_SERVER_USER].hosts</name>
<value>[OOZIE_SERVER_HOSTNAME]</value>
</property>
<property>
<name>hadoop.proxyuser.[OOZIE_SERVER_USER].groups</name>
<value>[USER_GROUPS_THAT_ALLOW_IMPERSONATION]</value>
</property>
Replace the capital letter sections with specific values and then restart Hadoop. The ExtJS library is optional (only required for the Oozie web-console to work)
All Oozie server scripts (=oozie-setup.sh=, oozied.sh , oozie-start.sh , oozie-run.sh and oozie-stop.sh ) run only under the Unix user that owns the Oozie installation directory, if necessary use sudo -u OOZIE_USER when invoking the scripts. As of Oozie 3.3.2, use of oozie-start.sh , oozie-run.sh , and oozie-stop.sh has been deprecated and will print a warning. The oozied.sh script should be used instead; passing it start , run , or stop as an argument will perform the behaviors of oozie-start.sh , oozie-run.sh , and oozie-stop.sh respectively.
Create a libext/ directory in the directory where Oozie was expanded. If using the ExtJS library copy the ZIP file to the libext/ directory. If hadoop and hcatalog libraries are not already included in the war, add the corresponding libraries to libext/ directory.
A “sharelib create -fs fs_default_name [-locallib sharelib]” command is available when running oozie-setup.sh for uploading new sharelib into hdfs where the first argument is the default fs name and the second argument is the Oozie sharelib to install, it can be a tarball or the expanded version of it. If the second argument is omitted, the Oozie sharelib tarball from the Oozie installation directory will be used. Upgrade command is deprecated, one should use create command to create new version of sharelib. Sharelib files are copied to new lib_ directory. At start, server picks the sharelib from latest time-stamp directory. While starting server also purge sharelib directory which is older than sharelib retention days (defined as oozie.service.ShareLibService.temp.sharelib.retention.days and 7 days is default).
“prepare-war [-d directory]” command is for creating war files for oozie with an optional alternative directory other than libext.
db create|upgrade|postupgrade -run [-sqlfile ] command is for create, upgrade or postupgrade oozie db with an optional sql file
Run the oozie-setup.sh script to configure Oozie with all the components added to the libext/ directory.
$ bin/oozie-setup.sh prepare-war [-d directory] [-secure]
sharelib create -fs <FS_URI> [-locallib <PATH>]
sharelib upgrade -fs <FS_URI> [-locallib <PATH>]
db create|upgrade|postupgrade -run [-sqlfile <FILE>]
The -secure option will configure Oozie to use HTTP (SSL).
Create the Oozie DB using the ‘ooziedb.sh’ command line tool:
$ bin/ooziedb.sh create -sqlfile oozie.sql -runValidate DB Connection.
DONE
Check DB schema does not exist
DONE
Check OOZIE_SYS table does not exist
DONE
Create SQL schema
DONE
DONE
Create OOZIE_SYS table
DONE
Oozie DB has been created for Oozie version ‘3.2.0’
$
- Start Oozie as a daemon process run:
$ bin/oozied.sh start
- To start Oozie as a foreground process run:
$ bin/oozied.sh run
- Using the Oozie command line tool check the status of Oozie:
$ bin/oozie admin -oozie http://localhost:11000/oozie -status
- Using a browser go to the Oozie web console , Oozie status should be NORMAL .
Client Installation
System Requirements
- Unix (tested in Linux and Mac OS X)
- Java 1.6+. The Java 1.6+ bin directory should be in the command path.
Copy and expand the oozie-client TAR.GZ file bundled with the distribution. Add the bin/ directory to the PATH . The Oozie server installation includes the Oozie client. The Oozie client should be installed in remote machines only.
Oozie Definitions
- Action: An execution/computation task (Map-Reduce job, Pig job, a shell command). It can also be referred as task or ‘action node’.
- Workflow: A collection of actions arranged in a control dependency DAG (Direct Acyclic Graph). “control dependency” from one action to another means that the second action can’t run until the first action has completed.
- Workflow Definition: A programmatic description of a workflow that can be executed. A workflow definition is a DAG with control flow nodes (start, end, decision, fork, join, kill) or action nodes (map-reduce, pig, etc.), nodes are connected by transitions arrows. The workflow definition language is XML based and it is called hPDL (Hadoop Process Definition Language).
- Workflow Definition Language: The language used to define a Workflow Definition.
- Workflow Job: An executable instance of a workflow definition.
- Workflow Engine: A system that executes workflows jobs. It can also be referred as a DAG engine.
Oozie Specification Highlights
A Workflow application is DAG that coordinates the following types of actions: Hadoop, Pig, and sub-workflows. Flow control operations within the workflow applications can be done using decision, fork and join nodes. Cycles in workflows are not supported.
Actions and decisions can be parameterized with job properties, actions output (i.e. Hadoop counters) and file information (file exists, file size, etc). Formal parameters are expressed in the workflow definition as ${VAR} variables. A Workflow application is a ZIP file that contains the workflow definition (an XML file), all the necessary files to run all the actions: JAR files for Map/Reduce jobs, shells for streaming Map/Reduce jobs, native libraries, Pig scripts, and other resource files.
Before running a workflow job, the corresponding workflow application must be deployed in Oozie. Deploying workflow application and running workflow jobs can be done via command line tools, a WS API and a Java API.
Monitoring the system and workflow jobs can be done via a web console, command line tools, a WS API and a Java API. When submitting a workflow job, a set of properties resolving all the formal parameters in the workflow definitions must be provided. This set of properties is a Hadoop configuration.
Possible states for a workflow jobs are: PREP , RUNNING , SUSPENDED , SUCCEEDED , KILLED and FAILED . In the case of a action start failure in a workflow job, depending on the type of failure, Oozie will attempt automatic retries, it will request a manual retry or it will fail the workflow job.
Oozie can make HTTP callback notifications on action start/end/failure events and workflow end/failure events. In the case of workflow job failure, the workflow job can be resubmitted skipping previously completed actions. Before doing a resubmission the workflow application could be updated with a patch to fix a problem in the workflow application code.
Oozie does not support cycles in workflow definitions, workflow definitions must be a strict DAG. At workflow application deployment time, if Oozie detects a cycle in the workflow definition it must fail the deployment.
Workflow nodes are classified in control flow nodes and action nodes:
- Control flow nodes: nodes that control the start and end of the workflow and workflow job execution path.
- Action nodes: nodes that trigger the execution of a computation/processing task.
Node names and transitions must be conform to the following pattern =[a-zA-Z][\-_a-zA-Z0-0]*=, of up to 20 characters long.
Control Flow Nodes
Control flow nodes define the beginning and the end of a workflow (the start , end and kill nodes) and provide a mechanism to control the workflow execution path (the decision , fork and join nodes).
Start Control Node – The start node is the entry point for a workflow job, it indicates the first workflow node the workflow job must transition to. When a workflow is started, it automatically transitions to the node specified in the start . A workflow definition must have one start node.
Syntax:
<workflow-app name=”[WF-DEF-NAME]” xmlns=”uri:oozie:workflow:0.1″>
…
<start to=”[NODE-NAME]”/>
…
</workflow-app>
The to attribute is the name of first workflow node to execute.
Example:
<workflow-app name=”foo-wf” xmlns=”uri:oozie:workflow:0.1″>
…
<start to=”firstHadoopJob”/>
…
</workflow-app>
End Control Node – The end node is the end for a workflow job, it indicates that the workflow job has completed successfully. When a workflow job reaches the end it finishes successfully (SUCCEEDED). If one or more actions started by the workflow job are executing when the end node is reached, the actions will be killed. In this scenario the workflow job is still considered as successfully run. A workflow definition must have one end node.
Syntax:
<workflow-app name=”[WF-DEF-NAME]” xmlns=”uri:oozie:workflow:0.1″>
…
<end name=”[NODE-NAME]”/>
…
</workflow-app>
The name attribute is the name of the transition to do to end the workflow job.
Example:
<workflow-app name=”foo-wf” xmlns=”uri:oozie:workflow:0.1″>
…
<end name=”end”/>
</workflow-app>
Kill Control Node – The kill node allows a workflow job to kill itself. When a workflow job reaches the kill it finishes in error (KILLED). If one or more actions started by the workflow job are executing when the kill node is reached, the actions will be killed. A workflow definition may have zero or more kill nodes.
Syntax:
<workflow-app name=”[WF-DEF-NAME]” xmlns=”uri:oozie:workflow:0.1″>
…
<kill name=”[NODE-NAME]”>
<message>[MESSAGE-TO-LOG]</message>
</kill>
…
</workflow-app>
The name attribute in the kill node is the name of the Kill action node. The content of the message element will be logged as the kill reason for the workflow job. A kill node does not have transition elements because it ends the workflow job, as KILLED .
Example:
<workflow-app name=”foo-wf” xmlns=”uri:oozie:workflow:0.1″>
…
<kill name=”killBecauseNoInput”>
<message>Input unavailable</message>
</kill>
…
</workflow-app>
Decision Control Node – A decision node enables a workflow to make a selection on the execution path to follow. The behavior of a decision node can be seen as a switch-case statement. A decision node consists of a list of predicates-transition pairs plus a default transition. Predicates are evaluated in order or appearance until one of them evaluates to true and the corresponding transition is taken. If none of the predicates evaluates to true the default transition is taken.
Predicates are JSP Expression Language (EL) expressions that resolve into a boolean value, true or false . For example:
${fs:fileSize(‘/usr/foo/myinputdir’) gt 10 * GB}
Syntax:
<workflow-app name=”[WF-DEF-NAME]” xmlns=”uri:oozie:workflow:0.1″>
…
<decision name=”[NODE-NAME]”>
<switch>
<case to=”[NODE_NAME]”>[PREDICATE]</case>
…
<case to=”[NODE_NAME]”>[PREDICATE]</case>
<default to=”[NODE_NAME]”/>
</switch>
</decision>
…
</workflow-app>
The name attribute in the decision node is the name of the decision node. Each case elements contains a predicate and a transition name. The predicate ELs are evaluated in order until one returns true and the corresponding transition is taken. The default element indicates the transition to take if none of the predicates evaluates to true . All decision nodes must have a default element to avoid bringing the workflow into an error state if none of the predicates evaluates to true.
Example:
<workflow-app name=”foo-wf” xmlns=”uri:oozie:workflow:0.1″>
…
<decision name=”mydecision”>
<switch>
<case to=”reconsolidatejob”>
${fs:fileSize(secondjobOutputDir) gt 10 * GB}
</case> <case to=”rexpandjob”>
${fs:fileSize(secondjobOutputDir) lt 100 * MB}
</case>
<case to=”recomputejob”>
${ hadoop:counters(‘secondjob’)[RECORDS][REDUCE_OUT] lt 1000000 }
</case>
<default to=”end”/>
</switch>
</decision>
…
</workflow-app>
Fork and Join Control Nodes – A fork node splits one path of execution into multiple concurrent paths of execution. A join node waits until every concurrent execution path of a previous fork node arrives to it. The fork and join nodes must be used in pairs. The join node assumes concurrent execution paths are children of the same fork node.
Syntax:
<workflow-app name=”[WF-DEF-NAME]” xmlns=”uri:oozie:workflow:0.1″>
…
<fork name=”[FORK-NODE-NAME]”>
<path start=”[NODE-NAME]” />
…
<path start=”[NODE-NAME]” />
</fork>
…
<join name=”[JOIN-NODE-NAME]” to=”[NODE-NAME]” />
…
</workflow-app>
The name attribute in the fork node is the name of the workflow fork node. The start attribute in the path elements in the fork node indicate the name of the workflow node that will be part of the concurrent execution paths.
The name attribute in the join node is the name of the workflow join node. The to attribute in the join node indicates the name of the workflow node that will executed after all concurrent execution paths of the corresponding fork arrive to the join node.
Example:
<workflow-app name=”sample-wf” xmlns=”uri:oozie:workflow:0.1″>
…
<fork name=”forking”>
<path start=”firstparalleljob”/>
<path start=”secondparalleljob”/>
</fork>
<action name=”firstparallejob”>
<map-reduce>
<job-tracker>foo:8021</job-tracker>
<name-node>bar:8020</name-node>
<job-xml>job1.xml</job-xml>
</map-reduce>
<ok to=”joining”/>
<error to=”kill”/>
</action>
<action name=”secondparalleljob”>
<map-reduce>
<job-tracker>foo:8021</job-tracker>
<name-node>bar:8020</name-node>
<job-xml>job2.xml</job-xml>
</map-reduce>
<ok to=”joining”/>
<error to=”kill”/>
</action>
<join name=”joining” to=”nextaction”/>
…
</workflow-app>
By default, Oozie performs some validation that any forking in a workflow is valid and won’t lead to any incorrect behavior or instability. However, if Oozie is preventing a workflow from being submitted and you are very certain that it should work, you can disable forkjoin validation so that Oozie will accept the workflow. To disable this validation just for a specific workflow, simply set oozie.wf.validate.ForkJoin to false in the job.properties file. To disable this validation for all workflows, simply set =oozie.validate.ForkJoin= to false in the oozie-site.xml file. Disabling this validation is determined by the AND of both of these properties, so it will be disabled if either or both are set to false and only enabled if both are set to true (or not specified).
Workflow Action Nodes
Action nodes are the mechanism by which a workflow triggers the execution of a computation/processing task.
Action Basis – The following sub-sections define common behavior and capabilities for all action types.
All computation/processing tasks triggered by an action node are remote to Oozie. No workflow application specific computation/processing task is executed within Oozie.. All computation/processing tasks triggered by an action node are executed asynchronously by Oozie. For most types of computation/processing tasks triggered by workflow action, the workflow job has to wait until the computation/processing task completes before transitioning to the following node in the workflow. The exception is the fs action that is handled as a synchronous action.
Oozie can detect completion of computation/processing tasks by two different means, callbacks and polling. When a computation/processing tasks is started by Oozie, Oozie provides a unique callback URL to the task, the task should invoke the given URL to notify its completion.
For cases that the task failed to invoke the callback URL for any reason (i.e. a transient network failure) or when the type of task cannot invoke the callback URL upon completion, Oozie has a mechanism to poll computation/processing tasks for completion.
Actions Have 2 Transitions, =ok= and =error=. If a computation/processing task -triggered by a workflow- completes successfully, it transitions to ok. If a computation/processing task -triggered by a workflow- fails to complete successfully, its transitions to error.
If a computation/processing task exits in error, there computation/processing task must provide error-code and error-message information to Oozie. This information can be used from decision nodes to implement a fine grain error handling at workflow application level. Each action type must clearly define all the error codes it can produce.
Action Recovery – Oozie provides recovery capabilities when starting or ending actions. Once an action starts successfully Oozie will not retry starting the action if the action fails during its execution. The assumption is that the external system (i.e. Hadoop) executing the action has enough resilience to recover jobs once it has started (i.e. Hadoop task retries).
Java actions are a special case with regard to retries. Although Oozie itself does not retry Java actions should they fail after they have successfully started, Hadoop itself can cause the action to be restarted due to a map task retry on the map task running the Java application. For failures that occur prior to the start of the job, Oozie will have different recovery strategies depending on the nature of the failure.
If the failure is of transient nature, Oozie will perform retries after a pre-defined time interval. The number of retries and timer interval for a type of action must be pre-configured at Oozie level. Workflow jobs can override such configuration. Examples of a transient failures are network problems or a remote system temporary unavailable.
If the failure is of non-transient nature, Oozie will suspend the workflow job until an manual or programmatic intervention resumes the workflow job and the action start or end is retried. It is the responsibility of an administrator or an external managing system to perform any necessary cleanup before resuming the workflow job. If the failure is an error and a retry will not resolve the problem, Oozie will perform the error transition for the action.
Map-Reduce Action – The map-reduce action starts a Hadoop map/reduce job from a workflow. Hadoop jobs can be Java Map/Reduce jobs or streaming jobs. A map-reduce action can be configured to perform file system cleanup and directory creation before starting the map reduce job. This capability enables Oozie to retry a Hadoop job in the situation of a transient failure (Hadoop checks the non-existence of the job output directory and then creates it when the Hadoop job is starting, thus a retry without cleanup of the job output directory would fail).
The workflow job will wait until the Hadoop map/reduce job completes before continuing to the next action in the workflow execution path. The counters of the Hadoop job and job exit status (=FAILED=, KILLED or SUCCEEDED ) must be available to the workflow job after the Hadoop jobs ends. This information can be used from within decision nodes and other actions configurations.
The map-reduce action has to be configured with all the necessary Hadoop JobConf properties to run the Hadoop map/reduce job. Hadoop JobConf properties can be specified as part of
- the config-default.xml or
- JobConf XML file bundled with the workflow application or
- tag in workflow definition or
- Inline map-reduce action configuration or
- An implementation of OozieActionConfigurator specified by the tag in workflow definition.
The configuration properties are loaded in the following above order i.e. streaming , job-xml , configuration , and config-class , and the precedence order is later values override earlier values. Streaming and inline property values can be parameterized (templatized) using EL expressions. The Hadoop mapred.job.tracker and fs.default.name properties must not be present in the job-xml and inline configuration.
Adding Files and Archives for the Job – The file , archive elements make available, to map-reduce jobs, files and archives. If the specified path is relative, it is assumed the file or archiver are within the application directory, in the corresponding sub-path. If the path is absolute, the file or archive it is expected in the given absolute path. Files specified with the file element, will be symbolic links in the home directory of the task.
If a file is a native library (an ‘.so’ or a ‘.so.#’ file), it will be symlinked as and ‘.so’ file in the task running directory, thus available to the task JVM. To force a symlink for a file on the task running directory, use a ‘#’ followed by the symlink name. For example ‘mycat.sh#cat’.
Configuring the MapReduce action with Java code – Java code can be used to further configure the MapReduce action. This can be useful if you already have “driver” code for your MapReduce action, if you’re more familiar with MapReduce’s Java API, if there’s some configuration that requires logic, or some configuration that’s difficult to do in straight XML (e.g. Avro).
Create a class that implements the org.apache.oozie.action.hadoop.OozieActionConfigurator interface from the “oozie-sharelib-oozie” artifact. It contains a single method that receives a JobConf as an argument. Any configuration properties set on this JobConf will be used by the MapReduce action. The OozieActionConfigurator has this signature:
public interface OozieActionConfigurator {
public void configure(JobConf actionConf) throws OozieActionConfiguratorException;
}
where actionConf is the JobConf you can update. If you need to throw an Exception, you can wrap it in an OozieActionConfiguratorException , also in the “oozie-sharelib-oozie” artifact.
For example:
package com.example;import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobConf;
import org.apache.oozie.action.hadoop.OozieActionConfigurator;
import org.apache.oozie.action.hadoop.OozieActionConfiguratorException;
import org.apache.oozie.example.SampleMapper;
import org.apache.oozie.example.SampleReducer;
public class MyConfigClass implements OozieActionConfigurator {
@Override
public void configure(JobConf actionConf) throws OozieActionConfiguratorException {
if (actionConf.getUser() == null) {
throw new OozieActionConfiguratorException(“No user set”);
}
actionConf.setMapperClass(SampleMapper.class);
actionConf.setReducerClass(SampleReducer.class);
FileInputFormat.setInputPaths(actionConf, new Path(“/user/” + actionConf.getUser() + “/input-data”));
FileOutputFormat.setOutputPath(actionConf, new Path(“/user/” + actionConf.getUser() + “/output”));
…
}
}
To use your config class in your MapReduce action, simply compile it into a jar, make the jar available to your action, and specify the class name in the config-class element (this requires at least schema 0.5):
<workflow-app name=”[WF-DEF-NAME]” xmlns=”uri:oozie:workflow:0.5″>
…
<action name=”[NODE-NAME]”>
<map-reduce>
…
<job-xml>[JOB-XML-FILE]</job-xml>
<configuration>
<property>
<name>[PROPERTY-NAME]</name>
<value>[PROPERTY-VALUE]</value>
</property>
…
</configuration>
<config-class>com.example.MyConfigClass</config-class>
…
</map-reduce>
<ok to=”[NODE-NAME]”/>
<error to=”[NODE-NAME]”/>
</action>
…
</workflow-app>
Another example of this can be found in the “map-reduce” example that comes with Oozie. A useful tip: The initial JobConf passed to the configure method includes all of the properties listed in the configuration section of the MR action in a workflow. If you need to pass any information to your OozieActionConfigurator, you can simply put them here.
Streaming – Streaming information can be specified in the streaming element. The mapper and reducer elements are used to specify the executable/script to be used as mapper and reducer.
User defined scripts must be bundled with the workflow application and they must be declared in the files element of the streaming configuration. If the are not declared in the files element of the configuration it is assumed they will be available (and in the command PATH) of the Hadoop slave machines.
Some streaming jobs require Files found on HDFS to be available to the mapper/reducer scripts. This is done using the file and archive elements. The Mapper/Reducer can be overridden by a mapred.mapper.class or mapred.reducer.class properties in the job-xml file or configuration elements.
Pipes – Pipes information can be specified in the pipes element. A subset of the command line options which can be used while using the Hadoop Pipes Submitter can be specified via elements – map , reduce , inputformat , partitioner , writer , program .
The program element is used to specify the executable/script to be used. User defined program must be bundled with the workflow application. Some pipe jobs require Files found on HDFS to be available to the mapper/reducer scripts. Pipe properties can be overridden by specifying them in the job-xml file or configuration element.
Syntax
<workflow-app name=”[WF-DEF-NAME]” xmlns=”uri:oozie:workflow:0.5″>
…
<action name=”[NODE-NAME]”>
<map-reduce>
<job-tracker>[JOB-TRACKER]</job-tracker>
<name-node>[NAME-NODE]</name-node>
<prepare>
<delete path=”[PATH]”/>
…
<mkdir path=”[PATH]”/>
…
</prepare>
<streaming>
<mapper>[MAPPER-PROCESS]</mapper>
<reducer>[REDUCER-PROCESS]</reducer>
<record-reader>[RECORD-READER-CLASS]</record-reader>
<record-reader-mapping>[NAME=VALUE]</record-reader-mapping>
…
<env>[NAME=VALUE]</env>
…
</streaming>
<!– Either streaming or pipes can be specified for an action, not both –>
<pipes>
<map>[MAPPER]</map>
<reduce>[REDUCER]</reducer>
<inputformat>[INPUTFORMAT]</inputformat>
<partitioner>[PARTITIONER]</partitioner>
<writer>[OUTPUTFORMAT]</writer>
<program>[EXECUTABLE]</program>
</pipes>
<job-xml>[JOB-XML-FILE]</job-xml>
<configuration>
<property>
<name>[PROPERTY-NAME]</name>
<value>[PROPERTY-VALUE]</value>
</property>
…
</configuration>
<config-class>com.example.MyConfigClass</config-class>
<file>[FILE-PATH]</file>
…
<archive>[FILE-PATH]</archive>
…
</map-reduce> <ok to=”[NODE-NAME]”/>
<error to=”[NODE-NAME]”/>
</action>
…
</workflow-app>
The prepare element, if present, indicates a list of paths to delete before starting the job. This should be used exclusively for directory cleanup or dropping of hcatalog table partitions for the job to be executed. The delete operation will be performed in the fs.default.name filesystem for hdfs URIs. The format to specify a hcatalog table partition URI is hcat://[metastore server]:[port]/[database name]/[table name]/[partkey1]=[value];[partkey2]=[value]. In case of a hcatalog URI, the hive-site.xml needs to be shipped using file tag and the hcatalog and hive jars need to be placed in workflow lib directory or specified using archive tag.
The job-xml element, if present, must refer to a Hadoop JobConf job.xml file bundled in the workflow application. By default the job.xml file is taken from the workflow application namenode, regardless the namenode specified for the action. To specify a job.xml on another namenode use a fully qualified file path. The job-xml element is optional and as of schema 0.4, multiple job-xml elements are allowed in order to specify multiple Hadoop JobConf job.xml files.
The configuration element, if present, contains JobConf properties for the Hadoop job. Properties specified in the configuration element override properties specified in the file specified in the job-xml element. As of schema 0.5, the config-class element, if present, contains a class that implements OozieActionConfigurator that can be used to further configure the MapReduce job. Properties specified in the config-class class override properties specified in configuration element.
External Stats can be turned on/off by specifying the property oozie.action.external.stats.write as true or false in the configuration element of workflow.xml. The default value for this property is false. The file element, if present, must specify the target symbolic link for binaries by separating the original file and target with a # (file#target-sym-link). This is not required for libraries. The mapper and reducer process for streaming jobs, should specify the executable command with URL encoding. e.g. ‘%’ should be replaced by ‘%25’.
Example:
<workflow-app name=”foo-wf” xmlns=”uri:oozie:workflow:0.1″>
…
<action name=”myfirstHadoopJob”>
<map-reduce>
<job-tracker>foo:8021</job-tracker>
<name-node>bar:8020</name-node>
<prepare>
<delete path=”hdfs://foo:8020/usr/tucu/output-data”/>
</prepare>
<job-xml>/myfirstjob.xml</job-xml>
<configuration>
<property>
<name>mapred.input.dir</name>
<value>/usr/tucu/input-data</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>/usr/tucu/input-data</value>
</property>
<property>
<name>mapred.reduce.tasks</name>
<value>${firstJobReducers}</value>
</property>
<property>
<name>oozie.action.external.stats.write</name>
<value>true</value>
</property>
</configuration>
</map-reduce>
<ok to=”myNextAction”/>
<error to=”errorCleanup”/>
</action>
…
</workflow-app>
In the above example, the number of Reducers to be used by the Map/Reduce job has to be specified as a parameter of the workflow job configuration when creating the workflow job.
Streaming Example:
<workflow-app name=”sample-wf” xmlns=”uri:oozie:workflow:0.1″>
…
<action name=”firstjob”>
<map-reduce>
<job-tracker>foo:8021</job-tracker>
<name-node>bar:8020</name-node>
<prepare>
<delete path=”${output}”/>
</prepare>
<streaming>
<mapper>/bin/bash testarchive/bin/mapper.sh testfile</mapper>
<reducer>/bin/bash testarchive/bin/reducer.sh</reducer>
</streaming>
<configuration>
<property>
<name>mapred.input.dir</name>
<value>${input}</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>${output}</value>
</property>
<property>
<name>stream.num.map.output.key.fields</name>
<value>3</value>
</property>
</configuration>
<file>/users/blabla/testfile.sh#testfile</file>
<archive>/users/blabla/testarchive.jar#testarchive</archive>
</map-reduce>
<ok to=”end”/>
<error to=”kill”/>
</action>
…
</workflow-app>
Pipes Example:
<workflow-app name=”sample-wf” xmlns=”uri:oozie:workflow:0.1″>
…
<action name=”firstjob”>
<map-reduce>
<job-tracker>foo:8021</job-tracker>
<name-node>bar:8020</name-node>
<prepare>
<delete path=”${output}”/>
</prepare>
<pipes>
<program>bin/wordcount-simple#wordcount-simple</program>
</pipes>
<configuration>
<property>
<name>mapred.input.dir</name>
<value>${input}</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>${output}</value>
</property>
</configuration>
<archive>/users/blabla/testarchive.jar#testarchive</archive>
</map-reduce>
<ok to=”end”/>
<error to=”kill”/>
</action>
…
</workflow-app>
Pig Action – The pig action starts a Pig job. The workflow job will wait until the pig job completes before continuing to the next action. The pig action has to be configured with the job-tracker, name-node, pig script and the necessary parameters and configuration to run the Pig job.
A pig action can be configured to perform HDFS files/directories cleanup or HCatalog partitions cleanup before starting the Pig job. This capability enables Oozie to retry a Pig job in the situation of a transient failure (Pig creates temporary directories for intermediate data, thus a retry without cleanup would fail).
Hadoop JobConf properties can be specified as part of
- the config-default.xml or
- JobConf XML file bundled with the workflow application or
- tag in workflow definition or
- Inline pig action configuration.
The configuration properties are loaded in the following above order i.e. job-xml and configuration, and the precedence order is later values override earlier values. Inline property values can be parameterized (templatized) using EL expressions.
The Hadoop mapred.job.tracker and fs.default.name properties must not be present in the job-xml and inline configuration. As with Hadoop map-reduce jobs, it is possible to add files and archives to be available to the Pig job.
Syntax for Pig actions in Oozie schema 0.2:
<workflow-app name=”[WF-DEF-NAME]” xmlns=”uri:oozie:workflow:0.2″>
…
<action name=”[NODE-NAME]”>
<pig>
<job-tracker>[JOB-TRACKER]</job-tracker>
<name-node>[NAME-NODE]</name-node>
<prepare>
<delete path=”[PATH]”/>
…
<mkdir path=”[PATH]”/>
…
</prepare>
<job-xml>[JOB-XML-FILE]</job-xml>
<configuration>
<property>
<name>[PROPERTY-NAME]</name>
<value>[PROPERTY-VALUE]</value>
</property>
…
</configuration>
<script>[PIG-SCRIPT]</script>
<param>[PARAM-VALUE]</param>
…
<param>[PARAM-VALUE]</param>
<argument>[ARGUMENT-VALUE]</argument>
…
<argument>[ARGUMENT-VALUE]</argument>
<file>[FILE-PATH]</file>
…
<archive>[FILE-PATH]</archive>
…
</pig>
<ok to=”[NODE-NAME]”/>
<error to=”[NODE-NAME]”/>
</action>
…
</workflow-app>
Syntax for Pig actions in Oozie schema 0.1:
<workflow-app name=”[WF-DEF-NAME]” xmlns=”uri:oozie:workflow:0.1″>
…
<action name=”[NODE-NAME]”>
<pig>
<job-tracker>[JOB-TRACKER]</job-tracker>
<name-node>[NAME-NODE]</name-node>
<prepare>
<delete path=”[PATH]”/>
…
<mkdir path=”[PATH]”/>
…
</prepare>
<job-xml>[JOB-XML-FILE]</job-xml>
<configuration>
<property>
<name>[PROPERTY-NAME]</name>
<value>[PROPERTY-VALUE]</value>
</property>
…
</configuration>
<script>[PIG-SCRIPT]</script>
<param>[PARAM-VALUE]</param>
…
<param>[PARAM-VALUE]</param>
<file>[FILE-PATH]</file>
…
<archive>[FILE-PATH]</archive>
…
</pig>
<ok to=”[NODE-NAME]”/>
<error to=”[NODE-NAME]”/>
</action>
…
</workflow-app>
The prepare element, if present, indicates a list of paths to delete before starting the job. This should be used exclusively for directory cleanup or dropping of hcatalog table partitions for the job to be executed. The format to specify a hcatalog table partition URI is hcat://[metastore server]:[port]/[database name]/[table name]/[partkey1]=[value];[partkey2]=[value]. In case of a hcatalog URI, the hive-site.xml needs to be shipped using file tag and the hcatalog and hive jars need to be placed in workflow lib directory or specified using archive tag.
The job-xml element, if present, must refer to a Hadoop JobConf job.xml file bundled in the workflow application. The job-xml element is optional and as of schema 0.4, multiple job-xml elements are allowed in order to specify multiple Hadoop JobConf job.xml files.
The configuration element, if present, contains JobConf properties for the underlying Hadoop jobs. Properties specified in the configuration element override properties specified in the file specified in the job-xml element. External Stats can be turned on/off by specifying the property oozie.action.external.stats.write as true or false in the configuration element of workflow.xml. The default value for this property is false .
The inline and job-xml configuration properties are passed to the Hadoop jobs submitted by Pig runtime. The script element contains the pig script to execute. The pig script can be templatized with variables of the form ${VARIABLE} . The values of these variables can then be specified using the params element.
Oozie will perform the parameter substitution before firing the pig job. This is different from the parameter substitution mechanism provided by Pig , which has a few limitations. The params element, if present, contains parameters to be passed to the pig script. In Oozie schema 0.2: The arguments element, if present, contains arguments to be passed to the pig script. All the above elements can be parameterized (templatized) using EL expressions.
Example for Oozie schema 0.2:
<workflow-app name=”sample-wf” xmlns=”uri:oozie:workflow:0.2″>
…
<action name=”myfirstpigjob”>
<pig>
<job-tracker>foo:8021</job-tracker>
<name-node>bar:8020</name-node>
<prepare>
<delete path=”${jobOutput}”/>
</prepare>
<configuration>
<property>
<name>mapred.compress.map.output</name>
<value>true</value>
</property>
<property>
<name>oozie.action.external.stats.write</name>
<value>true</value>
</property>
</configuration>
<script>/mypigscript.pig</script>
<argument>-param</argument>
<argument>INPUT=${inputDir}</argument>
<argument>-param</argument>
<argument>OUTPUT=${outputDir}/pig-output3</argument>
</pig>
<ok to=”myotherjob”/>
<error to=”errorcleanup”/>
</action>
…
</workflow-app>
Example for Oozie schema 0.1:
<workflow-app name=”sample-wf” xmlns=”uri:oozie:workflow:0.1″>
…
<action name=”myfirstpigjob”>
<pig>
<job-tracker>foo:8021</job-tracker>
<name-node>bar:8020</name-node>
<prepare>
<delete path=”${jobOutput}”/>
</prepare>
<configuration>
<property>
<name>mapred.compress.map.output</name>
<value>true</value>
</property>
</configuration>
<script>/mypigscript.pig</script>
<param>InputDir=/home/tucu/input-data</param>
<param>OutputDir=${jobOutput}</param>
</pig>
<ok to=”myotherjob”/>
<error to=”errorcleanup”/>
</action>
…
</workflow-app>
Fs (HDFS) action – The fs action allows to manipulate files and directories in HDFS from a workflow application. The supported commands are move , delete , mkdir , chmod , touchz and chgrp. The FS commands are executed synchronously from within the FS action, the workflow job will wait until the specified file commands are completed before continuing to the next action.
Path names specified in the fs action can be parameterized (templatized) using EL expressions. Path name should be specified as a absolute path. In case of move , delete , chmod and chgrp commands, a glob pattern can also be specified instead of an absolute path. For move , glob pattern can only be specified for source path and not the target.
Each file path must specify the file system URI, for move operations, the target must not specified the system URI. All the commands within fs action do not happen atomically, if a fs action fails half way in the commands being executed, successfully executed commands are not rolled back. The fs action, before executing any command must check that source paths exist and target paths don’t exist (constraint regarding target relaxed for the move action. See below for details), thus failing before executing any command. Therefore the validity of all paths specified in one fs action are evaluated before any of the file operation are executed. Thus there is less chance of an error occurring while the fs action executes.
Syntax:
<workflow-app name=”[WF-DEF-NAME]” xmlns=”uri:oozie:workflow:0.5″>
…
<action name=”[NODE-NAME]”>
<fs>
<delete path='[PATH]’/>
…
<mkdir path='[PATH]’/>
…
<move source='[SOURCE-PATH]’ target='[TARGET-PATH]’/>
…
<chmod path='[PATH]’ permissions='[PERMISSIONS]’ dir-files=’false’ />
…
<touchz path='[PATH]’ />
…
<chgrp path='[PATH]’ group='[GROUP]’ dir-files=’false’ />
</fs>
<ok to=”[NODE-NAME]”/>
<error to=”[NODE-NAME]”/>
</action>
…
</workflow-app>
The delete command deletes the specified path, if it is a directory it deletes recursively all its content and then deletes the directory. The mkdir command creates the specified directory, it creates all missing directories in the path. If the directory already exist it does a no-op. In the move command the source path must exist. The following scenarios are addressed for a move :
- The file system URI(e.g. hdfs://{nameNode}) can be skipped in the target path. It is understood to be the same as that of the source. But if the target path does contain the system URI, it cannot be different than that of the source.
- The parent directory of the target path must exist
- For the target path, if it is a file, then it must not already exist.
- However, if the target path is an already existing directory, the move action will place your source as a child of the target directory.
The chmod command changes the permissions for the specified path. Permissions can be specified using the Unix Symbolic representation (e.g. -rwxrw-rw-) or an octal representation (755). When doing a chmod command on a directory, by default the command is applied to the directory and the files one level within the directory. To apply the chmod command to the directory, without affecting the files within it, the dir-files attribute must be set to false . To apply the chmod command recursively to all levels within a directory, put a recursive element inside the element.
The touchz command creates a zero length file in the specified path if none exists. If one already exists, then touchz will perform a touch operation. Touchz works only for absolute paths. The chgrp command changes the group for the specified path. When doing a chgrp command on a directory, by default the command is applied to the directory and the files one level within the directory. To apply the chgrp command to the directory, without affecting the files within it, the dir-files attribute must be set to false . To apply the chgrp command recursively to all levels within a directory, put a recursive element inside the element.
Example:
<workflow-app name=”sample-wf” xmlns=”uri:oozie:workflow:0.5″>
…
<action name=”hdfscommands”>
<fs>
<delete path=’hdfs://foo:8020/usr/tucu/temp-data’/>
<mkdir path=’archives/${wf:id()}’/>
<move source=’${jobInput}’ target=’archives/${wf:id()}/processed-input’/>
<chmod path=’${jobOutput}’ permissions=’-rwxrw-rw-‘ dir-files=’true’><recursive/></chmod>
<chgrp path=’${jobOutput}’ group=’testgroup’ dir-files=’true’><recursive/></chgrp>
</fs>
<ok to=”myotherjob”/>
<error to=”errorcleanup”/>
</action>
…
</workflow-app>
In the above example, a directory named after the workflow job ID is created and the input of the job, passed as workflow configuration parameter, is archived under the previously created directory. As of schema 0.4, if a name-node element is specified, then it is not necessary for any of the paths to start with the file system URI as it is taken from the name-node element. This is also true if the name-node is specified in the global section.
As of schema 0.4, zero or more job-xml elements can be specified; these must refer to Hadoop JobConf job.xml formatted files bundled in the workflow application. They can be used to set additional properties for the FileSystem instance.
As of schema 0.4, if a configuration element is specified, then it will also be used to set additional JobConf properties for the FileSystem instance. Properties specified in the configuration element override properties specified in the files specified by any job-xml elements.
Example:
<workflow-app name=”sample-wf” xmlns=”uri:oozie:workflow:0.4″>
…
<action name=”hdfscommands”>
<fs>
<name-node>hdfs://foo:8020</name-node>
<job-xml>fs-info.xml</job-xml>
<configuration>
<property>
<name>some.property</name>
<value>some.value</value>
</property>
</configuration>
<delete path=’/usr/tucu/temp-data’/>
</fs>
<ok to=”myotherjob”/>
<error to=”errorcleanup”/>
</action>
…
</workflow-app>
Oozie Coordinators
An Oozie coordinator schedules workflow executions based on a start-time and a frequency parameter, and it starts the workflow when all the necessary input data becomes available. If the input data is not available, the workflow execution is delayed until the input data becomes available. A coordinator is defined by a start and end time, a frequency, input and output data, and a workflow. A coordinator runs periodically from the start time until the end time, as shown in figure
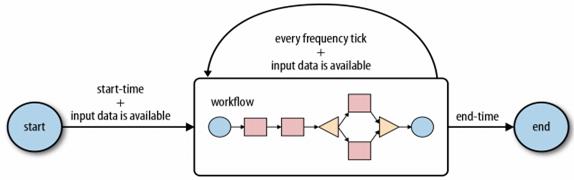
Beginning at the start time, the coordinator job checks if the required input data is available. When the input data becomes available, a workflow is started to process the input data, which on completion, produces the corresponding output data. This process is repeated at every tick of the frequency until the end time of the coordinator job. If the input data is not available for a workflow run, the execution of the workflow job will be delayed until the input data becomes available. Normally, both the input and output data used for a workflow execution are aligned with the coordinatortime frequency.
Application Deployment Model
An Oozie application is comprised of one file defining the logic of the application plus other files such as configuration and JAR files and scripts. A workflow application consists of a worklow.xml file and may have configuration files, Pig scripts, Hive scripts, JAR files, and more. Coordinator applications consist of a coordinator.xml file Bundle applications consist of a bundle.xml file.
Oozie applications are organized in directories, where a directory contains all files for the application. If files of an application need to reference each other, it is recommended to use relative paths. This simplifies the process of relocating the application to another directory if and when required. The JAR files required to execute the Hadoop jobs defined in the action of the workflow must be included in the classpath of Hadoop jobs. One basic approach is to copy the JARs into the lib/ subdirectory of the application directory. All JAR files in the lib/ subdirectory of the application directory are automatically included in the classpath of all Hadoop jobs started by Oozie.
When Oozie runs a job, it needs to read the XML file defining the application. Oozie expects all application files to be available in HDFS. This means that before running a job, you must copy the application files to HDFS. Deploying an Oozie application simply involves copying the directory with all the files required to run the application to HDFS.
The Oozie server is a Java web application that runs in a Java servlet container. By default, Oozie uses Apache Tomcat, which is an open source implementation of the Java servlet technology. Oozie clients, users, and other applications interact with the Oozie server using the oozie command-line tool, the Oozie Java client API, or the Oozie HTTP REST API. The oozie command-line tool and the Oozie Java API ultimately use the Oozie HTTP REST API to communicate with the Oozie server.
The Oozie server is a stateless web application. It does not keep any user or job information in memory between user requests. All the information about running and completed jobs is stored in a SQL database. When processing a user request for a job, Oozie retrieves the corresponding job state from the SQL database, performs the requested operation, and updates the SQL database with the new state of the job. This is a very common design pattern for web applications and helps Oozie support tens of thousands of jobs with relatively modest hardware. All of the job states are stored in the SQL database and the transactional nature of the SQL database ensures reliable behavior of Oozie jobs even if the Oozie server crashes or is shut down. When the Oozie server comes back up, it can continue to manage all the jobs based on their last known state.
